
Join 算法
为什么需要 Join 算法
为了避免不必要的数据信息重复,通常我们会在关系型数据库中,对表进行规范化处理,即:将不同的信息拆分为不同表进行存储。例如:我们会设计订单表 t_order,以及订单明细表 t_order_item,每个订单表 t_order 会有多个订单明细 t_order_item,如果我们想查询所有关于 Andy 的订单信息,这时候就需要将这 2 张表进行 join,获取到所有数据。
因此,我们需要使用 Join 来完成类似的需求,Join 可以在不丢失任何数据的情况下,对原始的元组信息 Tuple 进行重组,查询出我们需要的数据。
Join 运算符介绍
本节课程主要关注使用等值条件的内连接 Inner,暂时只讨论 2 张表关联的情况。通过这些基础的 Join 运算,后续我们稍作调整就可以支持其他类型的 Join 运算,对于多路连接运算(多张表关联),我们会在高级课程 15-721 中介绍。
通常,我们会将数据量更小的表作为执行计划树中的左表(或者叫外表),优化器会尝试估算 2 张表的数据量,然后生成对应的执行计划。如下是一个典型的 Join 执行计划树,所有运算符按照树形结构排列,数据从叶子节点流向父节点,最终所有数据汇总到根节点,根节点输出的就是查询的结果。
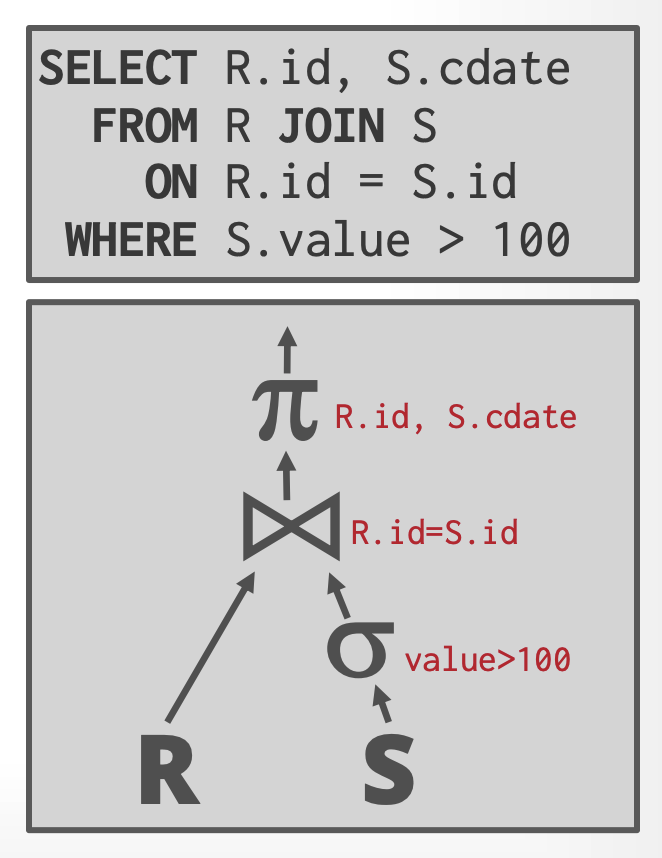
Join 运算符在执行时,需要考虑当前的节点需要向父节点输出哪些数据,上图中的箭头表示了数据输出。此外,Join 运算符还需要考虑执行的成本,如何判断一种 Join 算法比另一种更好?
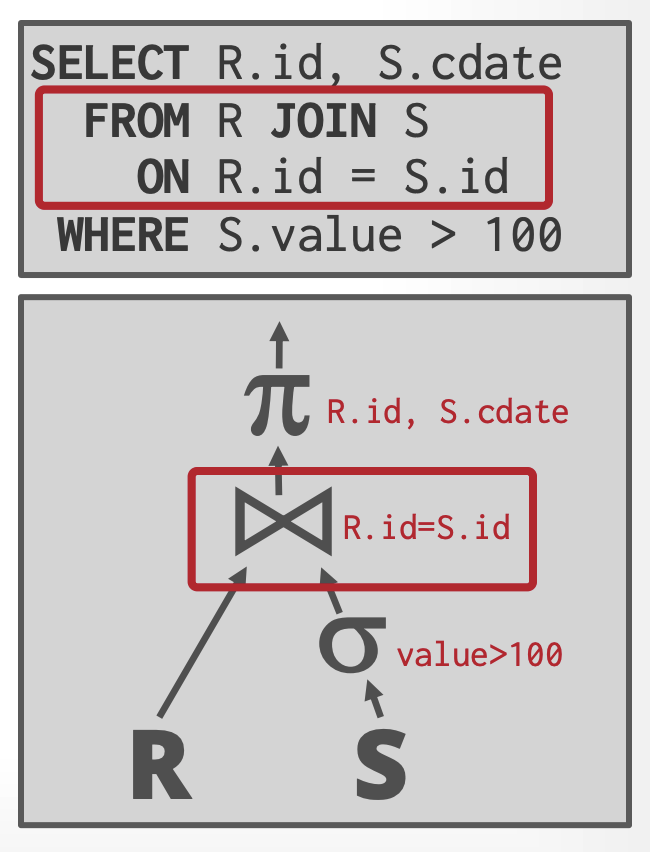
针对第一个问题——当前的节点需要向父节点输出哪些数据,我们参考上图的示例,对于所有属于 R 中的元组,我们使用 r 表示(r ∈ R),而属于 S 中的元组,我们使用 s 表示(s ∈ S)。我们根据 Join 关联条件 R.id = S.id 判断不同的元组组合是否满足条件,满足关联条件的数据会输出到父节点。
Join 输出的内容不是固定不变的,它可能会受查询处理模型、存储模型以及查询计划树的影响。例如,当存储模型是基于行的存储模型,或者基于列的存储模型时,Join 输出的元组数据可能是基于行或者列存储的数据。此外,根据查询计划树对于数据的要求,Join 运算符输出的可能是部分属性,而非关联表的全部属性。