
课程大纲
基础内容
- Relational Databases
- Storage
- Execution
- Concurrency Control
- Recovery
高级话题
- Distributed Databases
- Potpourri(大杂烩)
课程项目
课程项目采用 C++17 开发,需要自行学习 C++17 的编程知识。
所有课程项目都会使用 BusTub 学术 DBMS,它的主要架构如下:
- Disk-Oriented Storage:面向硬盘存储;
- Volcano-style Query Processing:Volcano 风格的查询处理器;
- Pluggable APIs:可插拔的 API;
- Currently does not support SQL:目前不支持 SQL。
数据库学术研究
- Database Group Meetings:https://db.cs.cmu.edu
- Advanced DBMS Developer Meetings:https://github.com/cmu-db/terrier
什么是数据库
什么是数据库?
Organized collection of inter-related data that models some aspect of the real-world. Databases are core the component of most computer applications.
数据库是以某种方式去进行关联的数据集合,可以对现实世界的某些方面进行建模,数据库不是那些随机分布在电脑上的零散文件,数据库中的数据之间通常都有某些共同的主题。它是大多数计算机应用的核心组件。
数据库示例
Create a database that models a digital music store to keep track of artists and albums.
创建一个模拟数字音乐商店的数据库,以跟踪艺术家和专辑。
Things we need store(我们需要存储如下信息):
- Information about Artists(艺术家的信息)
- What Albums those Artists released(艺术家发表的专辑)
那我们的数据库将如何存储这些信息呢?Store our database as comma-separated value(我们可以将数据库中的信息存储在 CSV 文件中)
(CSV) files that we manage in our own code.
- Use a separate file per entity(每一个实体使用一个单独的文件,例如:Artist 和 Album)
- The application has to parse the files each time they want to read/update records.(应用程序需要在读取或者更新记录时解析这些文件)
Create a database that models a digital music store. 创建一个数据库,为数字音乐商店建模。

Example: Get the year that Ice Cube went solo. 示例:找出 Ice Cube 单飞的年份。我们可以写一个 python 程序,遍历文件中的所有行,通过 parse 函数将行记录解析成数据,然后判断数组的第一个值是否等于 Ice Cube,相等则返回第二个值。
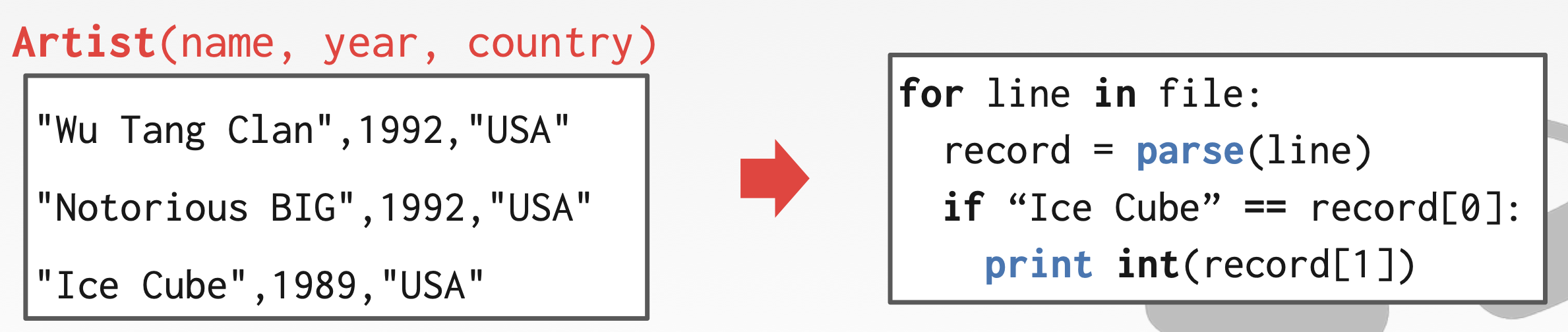
通过这种方式查找数据会存在一些问题,这些问题也是我们想要构建一个数据库管理系统的动机。具体问题如下:
DATA INTEGRITY(数据完整性)
- How do we ensure that the artist is the same for each album entry? 我们如何保证 artist 艺术家信息和 album 专辑中的艺术家信息相同?例如:Ice Cube 拼写错误,或者 Ice Cube 修改了自己的名字,album 表如何保证数据的一致?数据库中使用外键保证?
What if somebody overwrites the album year with an invalid string? 我们该如何保证对不同类型数据的存储是有效的,例如 year 输入了非法值
How do we store that there are multiple artists on an album? 如果一个专辑是多个艺术家创作的,我们该如何存储?
IMPLEMENTATION(实现)
How do you find a particular record? 如何去查找一条具体的记录?如果有 10 亿条数据,for 循环的方式就无法高效处理。
What if we now want to create a new application that uses the same database? 如何实现数据库逻辑的复用,示例中是使用 python 实现的数据库查询逻辑,其他语言无法复用。
What if two threads try to write to the same file at the same time? 如果两个线程同时尝试写入同一个数据文件,该如何处理?如果不进行特殊处理,很可能会出现记录的覆盖,第一个线程修改的内容将会丢失。
DURABILITY(持久性)
What if the machine crashes while our program is updating a record? 当程序正在更新一条记录时,此时程序或者机器宕机了,记录是更新完了,还是只更新了一半?我该如何推断它的正确状态呢?
What if we want to replicate the database on multiple machines for high availability? 因为机器的不可靠性,我们会考虑将数据库文件复制到不同的机器上以保证高可用。如果一台机器崩溃了,还可以使用备库提供服务。
数据库管理系统
基于以上存在的各种问题,我们需要有一个通用的数据库解决方案,也就是数据库管理系统 DBMS。那么什么是数据库管理系统呢?
A DBMS is software that allows applications to store and analyze information in a database.
数据库管理系统是一种专业软件,它允许应用程序在不关系底层实现的情况下,对数据库中的信息进行存储和分析。
A general-purpose DBMS is designed to allow the definition, creation, querying, update, and administration of databases.
本课程就是要设计一个通用的 DMBS,即设计用于允许应用程序来对数据库进行定义、创建、查询、更新以及管理。我们的主要目标是实现基于硬盘的数据库管理系统,当然也存在其他各种形式的数据库,例如内存数据库等。
早期数据库管理系统
Database applications were difficult to build and maintain. 数据库应用非常难以构建和维护。
Tight coupling between logical and physical layers. 逻辑层和物理层之间紧密耦合。
You have to (roughly) know what queries your app would execute before you deployed the database. 在部署数据库之前,你必须(粗略地)知道应用程序将执行哪些查询。
早期的数据库,你需要结合业务场景,通过数据库的 API 告诉数据库,我需要基于哈希表或者基于树的存储结构,当我们要销毁数据时,同样需要根据选择的存储结构,调用不同的数据库 API 进行操作。
关系模型
Ted Codd 发现了这个问题,为了避免人们重复地进行编码和重构,Ted Codd 提出了关系模型——A Relational Model of Data for Large Shared Data Banks。
Database abstraction to avoid this maintenance(Ted Codd 提出了关系模型的三要素,数据库抽象以避免这些人工维护):
- Store database in simple data structures. 将数据库转换为简单的数据结构进行存储,即关系(将所有表存储在数据库中以建立关系,表与表之间建立关系);
- Access data through high-level language. 通过高级语言访问数据库。
- Physical storage left up to implementation. 大型数据库的物理存储策略取决于数据库管理系统实现,存储结构对应用程序透明。逻辑层使用 SQL,物理存储层由数据库管理系统实现,这样实现了逻辑层和物理层的完全解耦,即使需要更换存储结构,应用程序也可以仍然使用同样的 SQL 访问。
数据模型
A data model is collection of concepts for describing the data in a database.
数据模型是描述数据库中数据的概念的集合。
A schema is a description of a particular collection of data, using a given data model.
模式是使用给定数据模型对特定数据集合的描述。
- Relational——关系模型,大部分的 DBMS 都采用了关系模型,本课程重点内容。
- Key/Value——NoSQL
- Graph——NoSQL
- Document——NoSQL
- Column-family——NoSQL
- Array / Matrix——数组和矩阵模型,通常会在机器学习中使用
- Hierarchical——层次数据模型(很古老的模型)
- Network——网络数据模型(很古老的模型)
关系模型三要素
关系数据模型包含了三个部分:
- Structure(关系结构): The definition of relations and their contents. 关系及其内容的定义。
- Integrity(数据完整性约束): Ensure the database’s contents satisfy constraints. 保证数据库内容满足约束条件。
- Manipulation(操纵): How to access and modify a database’s contents. 如何访问和修改数据库的内容。
关系模型中涉及到的关系和元祖的概念如下:
A relation is unordered set that contain the relationship of attributes that represent entities. 关系是一组无序的元素或记录,这些元素或记录的属性用来表示实体。
A tuple is a set of attribute values (also known as its domain) in the relation. 元组是关系中属性值的集合,通常用元组来表示关系模型中的一条记录。
- Values are (normally) atomic/scalar. Ted Codd 提出的关系模型中,值(通常)是原子/标量,不能是数组也不能是嵌套对象,但是随着关系模型的发展,也支持了数组和 JSON 对象存储。
- The special value NULL is a member of every domain. 每个元组中包含了一个特殊值 NULL。
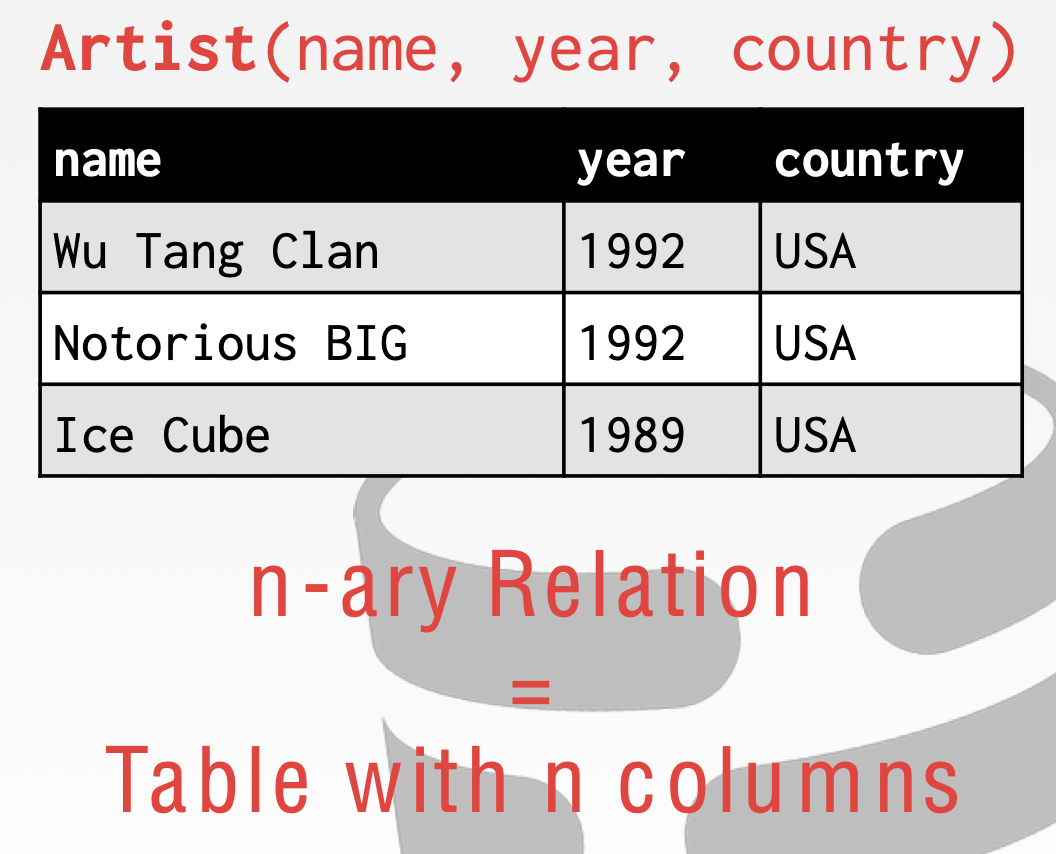
n-ary 关系其实就是一张表上有 n 列。在课程中,会使用到 relation 和 table 这两个术语,实际上他们是一回事。
关系模型之主键
A relation’s primary key uniquely identifies a single tuple. 关系中的主键能够唯一标识一个元组。
Some DBMSs automatically create an internal primary key if you don’t define one. 如果你没有定义主键,一些 DBMS 会自动创建一个内部的主键。
Auto-generation of unique integer primary keys: 自动生成唯一的整数主键的方式。
- SEQUENCE (SQL:2003)
- AUTO_INCREMENT (MySQL)
为了方便唯一定位一条记录,我们为 Artist 表增加了一个 id 作为主键。
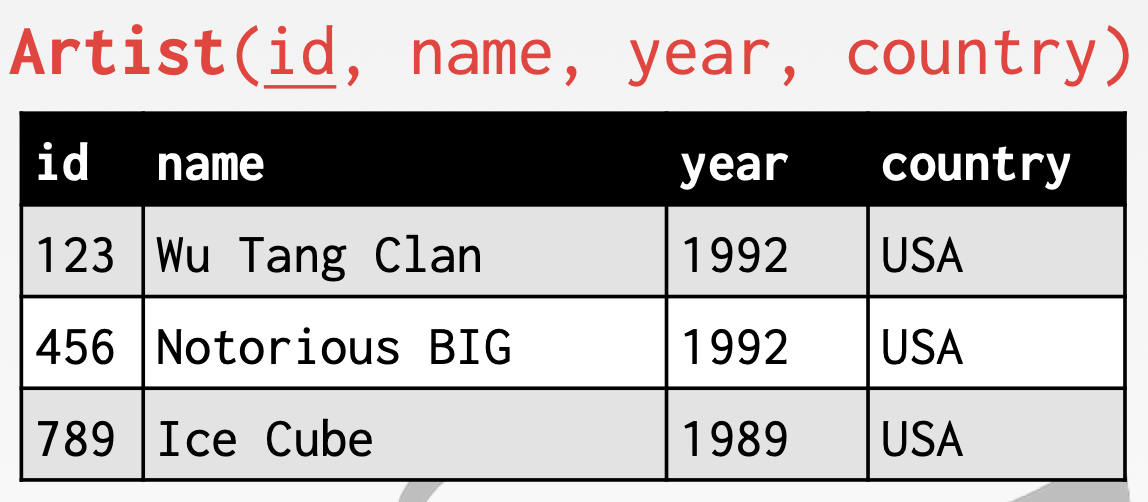
关系模型之外键
A foreign key specifies that an attribute from one relation has to map to a tuple in another relation. 外键是指将一个元组中的属性映射到另外一个元祖中的属性上,可以用来维护不同关系之间的数据一致性。
假设前面的示例中,我们想要在专辑表存储多位艺术家的名字,我们可以尝试将 artist 改成 artists,但是这就违背了原子性的要求,即每个字段必须只有一个值,如果存储多个值,使用中也会带来很多不便。

为了解决这个问题,我们可以考虑增加一张 ArtistAlbum 表,用来存储 Artist 和 Album 的映射关系,通过 ArtistAlbum 表,可以建立多对多的关系。另外,为了保证 ArtistAlbum 表的数据和主表的一致性,需要将对应字段设置成外键,保证数据的一致性。
数据操作语言 DML
How to store and retrieve information from a database. 如何从数据库存储及获取数据,通常有两种方式可以实现。
Procedural(过程式方式,关系代数 Relational Algebra,本课程的重点):
- The query specifies the (high-level) strategy the DBMS should use to find the desired result(查询指定高级别的策略,指导 DBMS 去查找想要的结果).
Non-Procedural(非过程式方式 关系演算 Relational Calculus):
- The query specifies only what data is wanted and not how to find it. 查询只指定想要什么数据,不提供查找的方式(声明式方式,SQL 就是一种声明式语言)。
关系代数
Fundamental operations to retrieve and manipulate tuples in a relation. 检索和操作关系中的元组的基本操作。
- Based on set algebra. 基于集合的代数。
Each operator takes one or more relations as its inputs and outputs a new relation. 每个操作符以一个或多个关系作为其输入,并输出一个新的关系。
- We can “chain” operators together to create more complex operations. 我们可以将操作符“链接”在一起,以创建更复杂的操作。
Ted Codd 提出了关系代数的七种基础运算符,这些运算是检索记录所必须的基础操作。值得一提的是,这种代数是基于集合的,这种集合是数据的无需列表或无需集合,里面的元素是可以重复的。

关系代数之 SELECT
Choose a subset of the tuples from a relation that satisfies a selection predicate. 从满足选择谓词的关系中选择元组的子集。
- Predicate acts as a filter to retain only tuples that fulfill its qualifying requirement. Predicate充当过滤器,只保留满足其限定要求的元组。
- Can combine multiple predicates using conjunctions / disjunctions. 可以使用连词/析取来组合多个谓词。conjunctions / disjunctions 如何理解?conjunctions 表示 and,可以用 ∧ 表示,disjunctions 表示 or,可以用 ∨ 表示。
下面是选择操作符的示例,我们可以单独使用 a_id = ‘a2’ 对结果集进行过滤,过滤之后可以得到一个结构和原始表格一致的新的结果集。此外,我们还可以组合多个谓词,来实现更复杂的选择逻辑。

1 | SELECT * FROM R WHERE a_id='a2' AND b_id>102; |
关系代数之 Projection
Generate a relation with tuples that contains only the specified attributes. 生成只包含指定属性的元组关系。
- Can rearrange attributes’ ordering. 可以重新排列属性的顺序。
- Can manipulate the values. 可以操作值。
下面的示例展示了先进行选择,再进行投影的操作,我们可以按照自己想要的顺序指定投影,可以在投影操作中进行运算,例如 b_id - 100,然后生成一个新的关系。

1 | SELECT b_id-100, a_id FROM R WHERE a_id = 'a2'; |
关系代数之 UNION
Generate a relation that contains all tuples that appear in either only one or both input relations. 生成一个关系,其中包含只出现在一个或两个输入关系中的所有元组。
Syntax: (R ∪ S)
当你想对两个关系进行 UNION 操作时,这两个关系必须具有相同的属性和相同的类型。
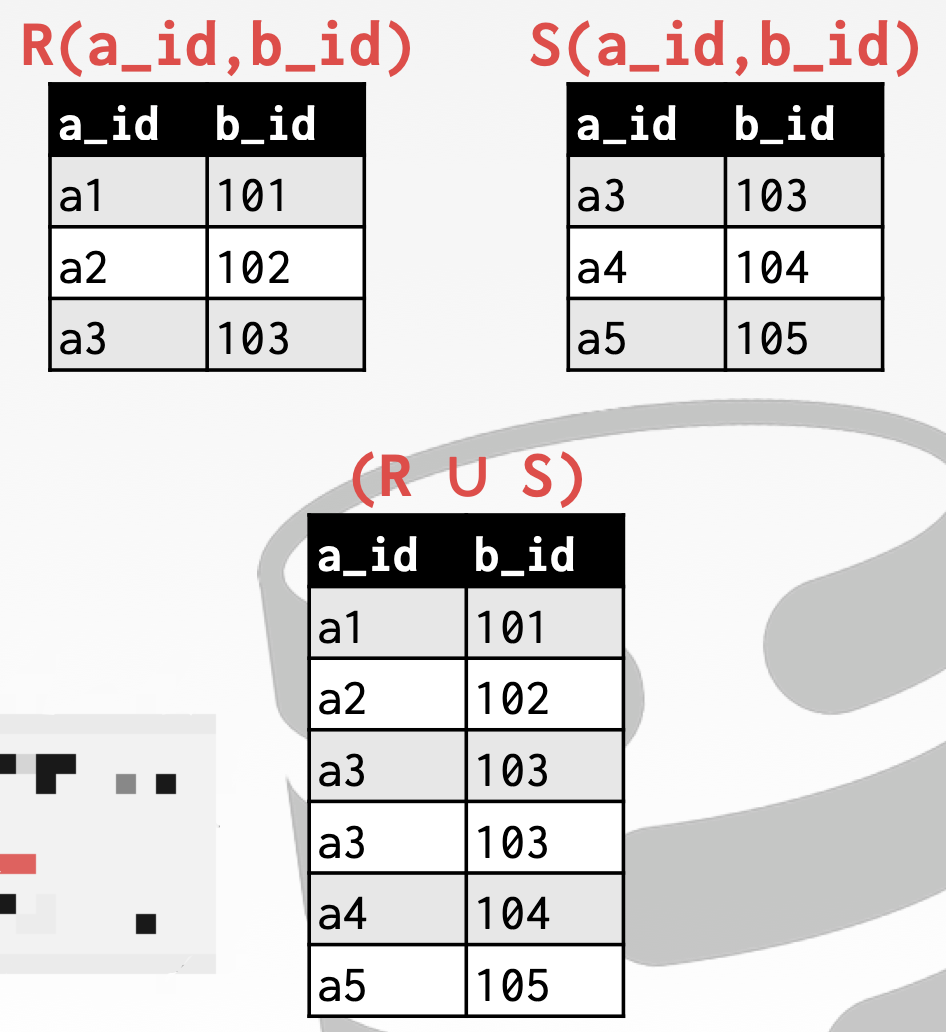
1 | (SELECT * FROM R) UNION ALL (SELECT * FROM S); |
关系代数之 INTERSECTION
Generate a relation that contains only the tuples that appear in both of the input relations. 生成一个只包含两个输入关系中出现的元组的关系。
Syntax: (R ∩ S)
和 UNION 运算一样,INTERSECTION 运算也要求两个关系必须具有相同的属性和相同的类型。
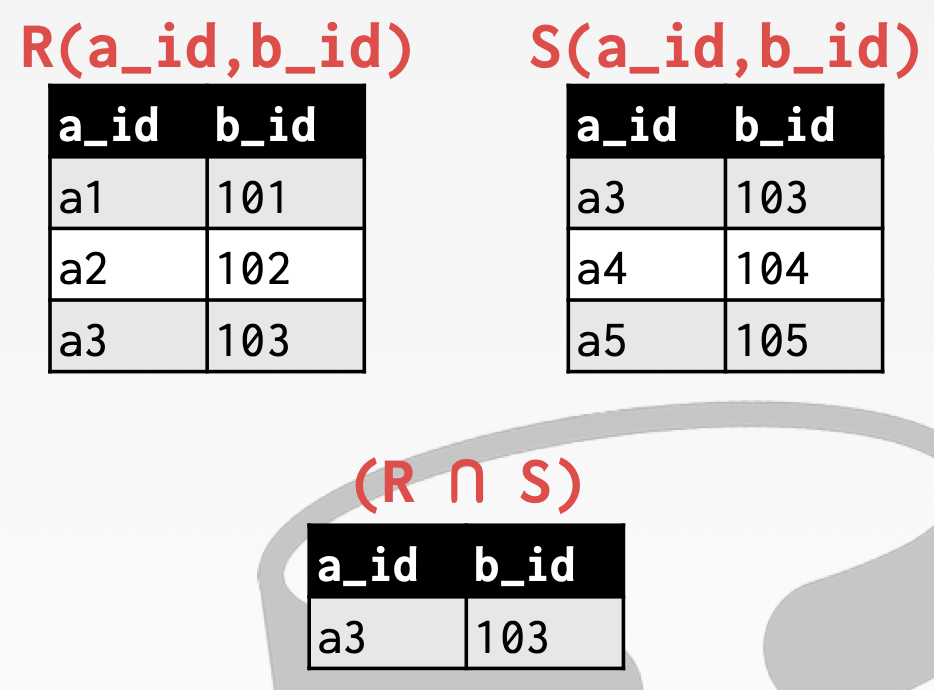
1 | (SELECT * FROM R) INTERSECT (SELECT * FROM S); |
关系代数之 DIFFERENCE
Generate a relation that contains only the tuples that appear in the first and not the second of the input relations. 生成一个只包含在输入关系的第一个而不是第二个中出现的元组的关系。
Syntax: (R – S)

1 | (SELECT * FROM R) EXCEPT (SELECT * FROM S); |
关系代数之 PRODUCT
Generate a relation that contains all possible combinations of tuples from the input relations. 从输入关系中生成一个包含所有可能的元组组合的关系。
Product 积运算,也叫笛卡尔积。
1 | Syntax: (R × S) |
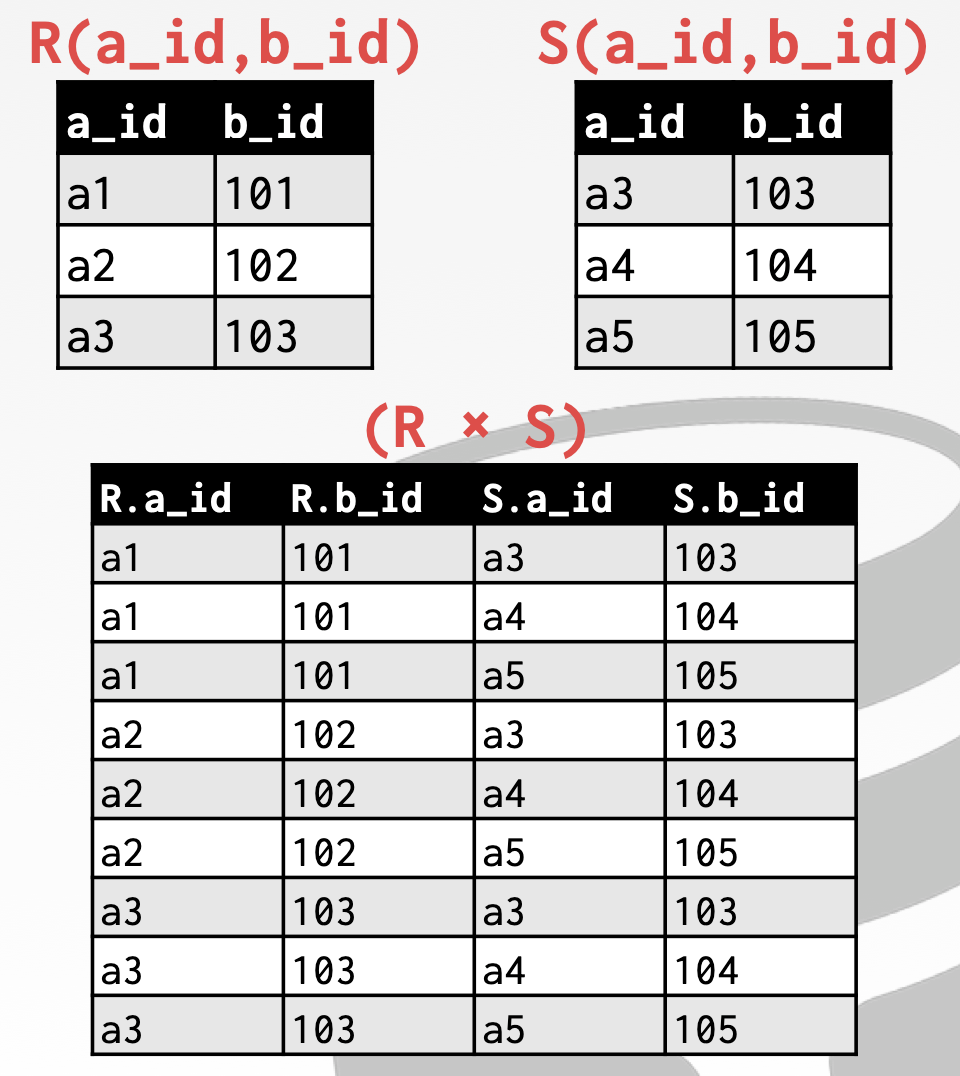
在 SQL 中,我们可以使用 CROSS JOIN,或者不写任何 JOIN 时,使用的就是笛卡尔积。
1 | SELECT * FROM R CROSS JOIN S; |
关系代数之 JOIN
Generate a relation that contains all tuples that are a combination of two tuples (one from each input relation) with a common value(s) for one or more attributes.
生成一个包含所有元组的关系,这些元组是两个元组(每个输入关系一个)的组合,具有一个或多个属性的公共值。
这里所说的 JOIN 指的是自然连接,而不是我们一般所说的 JOIN,自然连接会根据两个元组中相同名称,相同类型的属性进行关联。
1 | Syntax: (R ⋈ S) |
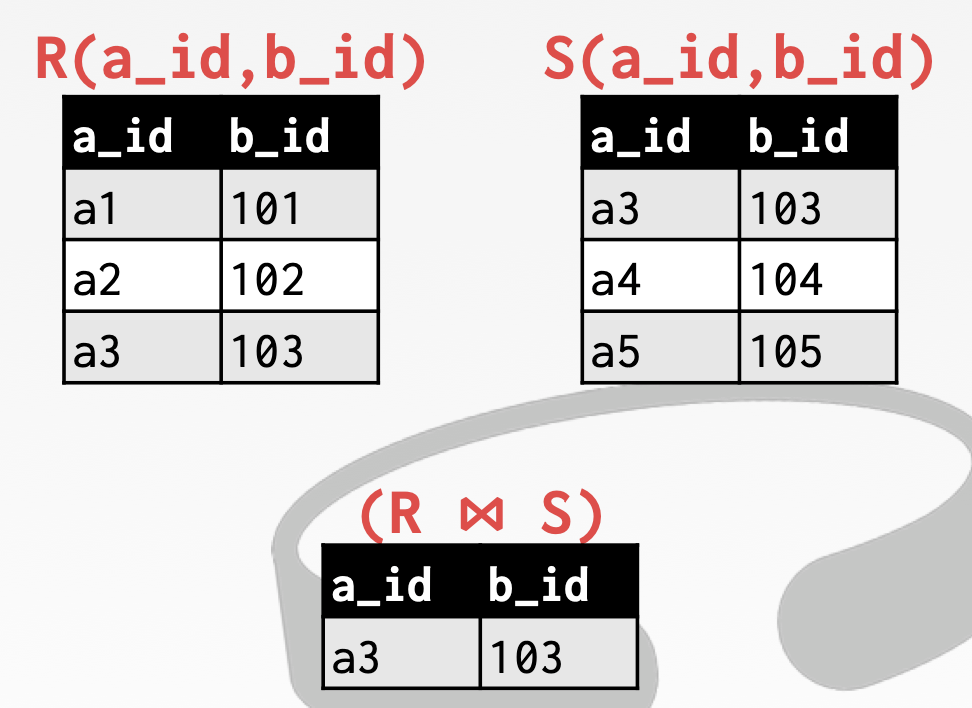
在 SQL 中,我们可以使用 NATURAL JOIN 进行关联,NATURAL JOIN 会自动根据相同名称的字段进行关联。
1 | SELECT * FROM R NATURAL JOIN S; |
关系代数之 EXTRA OPERATORS
Ted Codd 提出基础的关系模型运算符之后,后人又结合新的数据库发展提出了其他的运算符,主要包括如下的运算符。

关于 DBMS 一些观点
Relational algebra still defines the high-level steps of how to compute a query. 关系代数仍然定义了如何计算查询的高级步骤。
假设我们要对 R 和 S 进行 Join,我可以先对 R 和 S 进行自然连接,然后再使用 b_id = 102 条件进行过滤。也可以先对 S 表进行过滤,再使用 R 表和过滤结果进行自然连接。这两者的效率相差非常大。
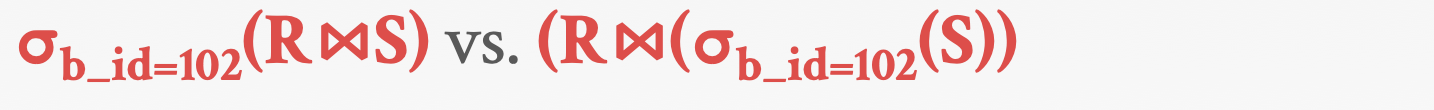
A better approach is to state the high-level answer that you want the DBMS to compute. 更好的方法是声明希望DBMS计算的高级答案。
- Retrieve the joined tuples from R and S where b_id equals 102. 从 R 和 S 中检索b_id = 102的连接元组。
对于应用程序来说,更好的方法是通过 SQL 声明我们要获取的结果,而不去关心数据库如何执行,具体的执行逻辑交给 DBMS 实现,根据不同的情况进行选择。
关系模型之查询
The relational model is independent of any query language implementation. 关系模型独立于任何查询语言实现。Ted Codd 提出关系模型时,甚至还没有 SQL 语言,后来 IBM 提出了 SQL 语言,才逐步成为事实标准。
SQL is the de facto standard. SQL是事实上的标准。
1 | for line in file: |
课程总结
Databases are ubiquitous. 数据库无处不在。
Relational algebra defines the primitives for processing queries on a relational database. 关系代数定义处理关系数据库查询的原语。
We will see relational algebra again when we talk about query optimization + execution. 在讨论查询优化 + 执行时,我们将再次看到关系代数。
思考:数据库是如何将 SQL 转换为关系代数,以及如何执行的?