

在现代分布式数据库的演进过程中,如何在保留关系型数据库(RDBMS)完整 SQL 生态与严格 ACID 事务语义的同时,实现云原生场景下的水平扩展与全局高可用,始终是数据库内核研发的核心挑战。传统单机关系型数据库(如原生 PostgreSQL、MySQL)受制于单节点计算与存储上限;早期 NoSQL 系统(如 Cassandra、HBase)虽解决了扩展性问题,却往往以牺牲强一致性与关系模型为代价。
本文基于卡内基梅隆大学(CMU)数据库组技术分享视频,以及 YugabyteDB 联合创始人兼 CTO Karthik Ranganathan(曾主导 Facebook 的 Cassandra 与 HBase 架构)对系统设计的阐述,并结合官方架构文档,对 YugabyteDB 的底层技术内核进行系统分析。该系统通过解耦查询引擎与存储引擎,复用 PostgreSQL 查询层,并在底层构建基于 RocksDB 与 Raft 共识协议的分布式文档存储 DocDB,从而在跨地域部署下实现高性能与单键线性一致性(Linearizability)。
架构演进背景:跨越 Aurora 与 Spanner 的设计鸿沟
在构建下一代分布式数据库时,团队重点对标了两类代表性云数据库架构:Amazon Aurora 与 Google Spanner。二者代表了截然不同的分布式系统设计路径。
Amazon Aurora 的写入扩展瓶颈
Amazon Aurora 在公有云中大规模验证了“计算与存储分离”与“日志即数据库(The Log is the Database)”的理念。其底层存储被重构为跨可用区(AZ)的分布式多副本系统,显著提升了存储可用性,并保持对 MySQL、PostgreSQL 协议的兼容。
但从分布式一致性视角看,Aurora 的计算层并未实现真正分布式化:
- 写入瓶颈:所有写入依赖单一主节点(
Master Node)。读取可通过只读副本(Read Replicas)横向扩展,但写入吞吐提升仍主要依赖垂直扩容(Scale Up)。 - 全局一致性不足:在跨区域(
Multi-Region)部署中,Aurora主要采用异步日志复制,难以在跨国网络延迟下提供严格全局ACID保障。
Google Spanner 的生态隔离与硬件依赖
与 Aurora 不同,Google Spanner 是自底向上设计的强一致、高可用(CP)全球分布式数据库。它使用基于 Paxos 的分布式共识在多数据中心间同步分片,并支持真正的水平多主写入。
但 Spanner 的大规模推广也面临现实限制:
- 时钟同步依赖专有硬件:
Spanner实现外部一致性(External Consistency)的重要前提是TrueTimeAPI,而TrueTime依赖Google数据中心内部署的原子钟(Atomic Clocks)与GPS接收器。在通用公有云(IaaS)或企业私有云中,这类硬件条件通常不具备。 - 早期
SQL兼容性较弱:在发布初期及较长一段时间内,Spanner对标准SQL方言与传统关系型驱动兼容有限,应用迁移与重构成本较高。
基于这些局限,YugabyteDB 确立了核心目标:在通用商用硬件上,以纯软件算法替代 TrueTime 原子钟机制,同时提供接近甚至超越 Aurora 的水平写扩展能力,并兼容 PostgreSQL 生态。
| 架构维度 | 传统 RDBMS | Amazon Aurora | Google Spanner | YugabyteDB |
|---|---|---|---|---|
| 计算与存储解耦 | 否 | 是 | 是 | 是 |
| 写入水平扩展 | 否 | 否(受限单主) | 是 | 是 |
| 事务时间戳同步 | 单机时钟 | 区域集中式时钟 | 专有硬件原子钟(TrueTime) | 纯软件混合逻辑时钟(HLC) |
| 开源生态/兼容性 | 标准生态(PG/MySQL) | 兼容(PG/MySQL) | 专有方言/逐步支持 SQL | 开源并复用 PostgreSQL |
系统宏观设计:松耦合双层架构
为实现上述目标,YugabyteDB 采用逻辑上明确解耦的双层架构(Two-Layer Architecture):
- 查询层(
Query Layer):无状态计算节点,负责客户端连接、协议解析、SQL语法分析、分布式查询规划与执行。目前提供兼容PostgreSQL的YSQLAPI,以及兼容Cassandra的YCQLAPI。 - 存储层(
Storage Layer):即DocDB。该层基于分布式共识与LSM-Tree,负责数据分片、跨节点复制、持久化与分布式事务协调。
YSQL 查询引擎:复用 PostgreSQL 源码的工程决策
在 YSQL 研发早期,团队曾尝试以 C++ 从零重写 PostgreSQL 连接器与查询规划器,沿用开发 YCQL 的技术路径。
重写 RDBMS 的复杂性陷阱
约五个月后,团队发现这一路径复杂度失控。成熟关系型数据库远不止基础 CRUD。例如 psql 中常见的 \d 命令,在 PostgreSQL 内部会转换为较长且复杂的查询语句,依赖大量系统视图与高级特性:
- 复杂
WHERE过滤(含正则匹配与IN条件)。 - 多级
CASE WHEN条件分支。 - 多系统目录表
LEFT JOIN与嵌套子查询。 - 特定
ORDER BY规则与系统函数(如pg_catalog.pg_table_is_visible())。
这意味着,即便只实现“建表并查看结构”这样的基础能力,也需要先补齐复杂 JOIN、聚合、系统目录查询等核心能力。对于企业常用的存储过程(Stored Procedures)、触发器(Triggers)、部分索引(Partial Indexes)、多维数组、JSONB 与视图(Views)等特性,重写成本极高。
源码复用与分布式改造
为解决上述问题,团队做出关键转向:放弃重写,直接在源码层引入 PostgreSQL 查询层(C 代码)。初始基于 PostgreSQL v10.4,并设计为模块化结构,以便后续合并 v11.2 及更高版本上游变更。
YSQL 保留了原生 PostgreSQL 的 Parser、Analyzer、Rewriter、Planner。这一路径使 YugabyteDB 快速继承了 PostgreSQL 二十余年积累的生态能力。
但把单机查询层接到分布式存储上,关键难点在于系统目录(System Catalogs)的分布式化。原生 PostgreSQL 中,元数据存储在本地磁盘。YugabyteDB 在初始化阶段通过改造版 initdb,将系统目录表重定向到 DocDB,作为独立分片(Tablet)管理;该分片同样受 Raft 保护,避免计算节点故障导致元数据丢失或不一致。运行期查询元数据时,引擎通过 RPC 路由到对应系统表 Leader 所在节点。
DocDB 存储内核:分片机制与 RocksDB 优化
DocDB 是 YugabyteDB 的基础存储层,受 Google Spanner 架构启发。其核心目标是高效管理数据分片(Tablets)、保障跨节点复制,并提供低延迟读写能力。
数据分片与路由
YugabyteDB 支持对 SQL 表进行透明分片,主要策略有两类:
- 哈希分片(
Hash-based Sharding):默认策略。对主键(Primary Key)哈希后分布到不同分片,适合打散写热点并均衡并发 I/O。 - 范围分片(
Range-based Sharding):按主键顺序切分,适合范围查询(如WHERE timestamp BETWEEN X AND Y),可减少跨节点聚合(Scatter-Gather)开销。
消除双重日志开销:禁用 RocksDB WAL
每个节点上的 Tablet 最终落盘于 RocksDB(LSM-Tree)。RocksDB 先写入内存 Memtable,再刷盘为 SSTable(Sorted String Table),具备较高顺序写吞吐。
若按传统分布式实现,会出现明显 I/O 放大:
- 写请求先通过
Raft Log在副本间复制。 - 各节点再将相同变更写入本地
RocksDB WAL以支持崩溃恢复。
这就是典型的双重日志惩罚(Double Journal Tax):同一数据两次强制落盘,带来更高延迟与带宽消耗。
YugabyteDB 通过工程改造规避该问题:DocDB 直接禁用 RocksDB 内部 WAL,并将 Raft Log 作为唯一事实来源(Source of Truth)。系统通过元数据追踪 Memtable 已覆盖的最大 Raft Sequence ID。节点故障恢复时,可据此按需回放缺失的 Raft 记录并完成状态重建,同时精确执行日志清理。
| 组件设计 | 传统分布式 RocksDB 架构 | YugabyteDB DocDB 优化架构 |
|---|---|---|
| 分布式日志 | Raft Log(共识与复制) | Raft Log(唯一持久化保障) |
| 单机预写日志 | RocksDB WAL(双写 I/O) | 已禁用 |
| 崩溃恢复依据 | 依赖 WAL,再校验共识 | 依据 Raft Sequence ID 回放 Raft Log |
| 垃圾回收策略 | WAL 与 Raft Log 独立清理 | Memtable 落盘后统一截断 Raft Log |
数据模型映射与 Packed Rows
关系表到底层 LSM-Tree 键值对的映射,是 DocDB 的关键设计点。早期实现采用“按列拆分”的细粒度模式:一行数据拆成多个键值对,键(DocKey)由哈希、主键、列标识(Column ID)与 MVCC 时间戳等字段组成。
这种方案对单列更新友好,但在宽表扫描与批量写入场景成本较高:例如 50 列表插入一行会生成约 50 个底层键值对,导致元数据膨胀和扫描寻址开销增加。
为此,自 v2.20 起引入 Packed Rows:将一行内多个非主键列在写入时序列化打包为单个宏观键值对。
INSERT:整行打包写入,批量导入吞吐显著提升。- 顺序扫描(
Sequential Scans):单次读取可解出整行,降低寻址与反复拼接开销。 UPDATE:部分列更新仍可作为增量键值对写入,避免重写整行。- 后台压缩(
Compactions):RocksDB合并SSTable时自动融合增量更新,重建紧凑行,兼顾更新效率与扫描性能。
跨地域延迟优化:面向强一致性的 Raft 增强
在地理分布部署(如跨国多地域)中,传统 Raft 的一致性读取常需 Leader 与多数派确认领导地位,这会引入额外网络往返延迟。
领导者租约(Leader Leases)
为降低强一致读延迟,YugabyteDB 引入 Leader Leases 机制,将“每次读取都做网络确认”转化为“在有效租约窗口内本地判定”:
- 租约获取:新
Leader当选后需等待旧Leader租约自然过期,再接管读写。 - 租约续期:
Leader在AppendEntries中携带续租信息;若超期且未获多数确认,则主动Step down。 - 时钟偏移控制:租约计算同时纳入
RPC延迟与最大时钟漂移(max-drift-between-nodes)约束,保证正确性。
在合法租约内,Leader 可直接依据本地状态处理读取,避免额外跨地域共识往返。
组提交(Group Commits)
面对高并发小写入,频繁发送小粒度 Raft 复制会放大网络与磁盘压力。DocDB 通过 Group Commits 在发送前聚合多个并发请求,形成批量 Raft 记录,以提升吞吐。
为保证批量提交中的顺序正确性,系统在内部共识标识中引入 Op ID,确保并发持久化过程仍满足严格偏序约束。
系统还支持动态 Leader 均衡(Leader Balancing),将分片主节点尽量分散到不同物理机,降低热点风险;在异地部署中,可通过亲和领导者(Affinitized Leaders)策略将主写入尽量靠近应用侧,进一步压缩写入延迟。
全局分布式事务:HLC 与两阶段提交
关系型数据库的关键能力之一,是支持跨分片、跨节点的原子事务。在纯软件架构下,YugabyteDB 通过 混合逻辑时钟(HLC) 与优化版两阶段提交(2PC)实现这一目标。
HLC:物理时间与逻辑时间融合
HLC 融合物理时钟(如 NTP 时间)与逻辑时钟(Lamport Clock)特性。每个节点维护本地 HLC(物理时间 + 逻辑计数器):
- 本地事务发生时,若物理时间前进,逻辑计数器归零;若物理时间不变,则递增计数器区分顺序。
- 节点间
RPC传播HLC;接收方若发现对端时间更“新”,会提升本地时间并更新逻辑计数。
这使系统在无需集中式时间戳服务(Timestamp Oracle)的情况下,仍可建立全局可比较的事务时间序关系,为 MVCC 与快照隔离(Snapshot Isolation)提供基础。
Transaction Status Tablet 驱动的提交流程
在时间序可判定后,YugabyteDB 使用去中心化优化 2PC,并引入 事务状态分片(Transaction Status Tablet) 降低协调者单点故障风险。
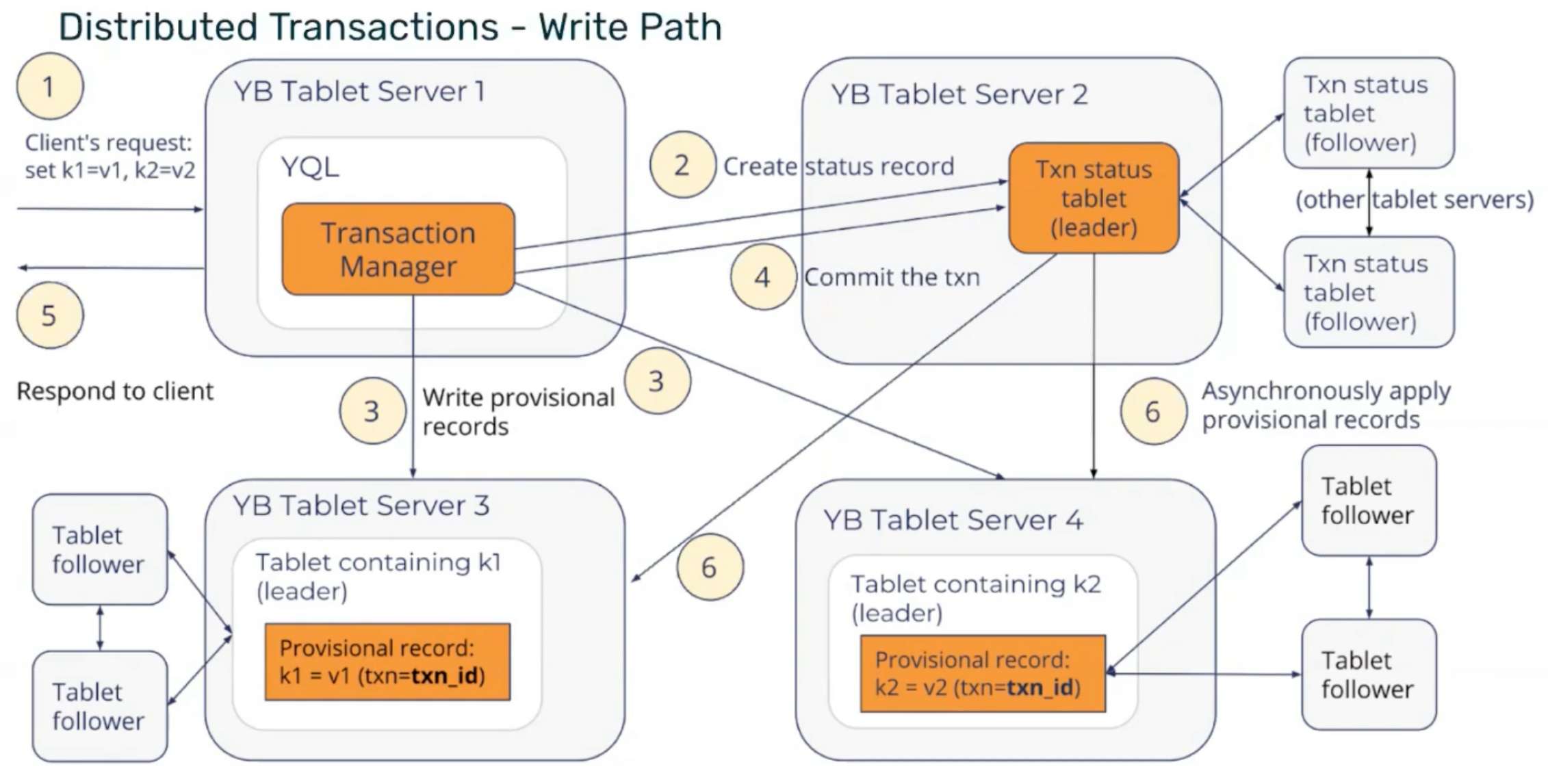
典型分布式写事务流程如下:
- 初始化:客户端
BEGIN后,协调节点生成全局事务 ID,并在状态分片写入Pending记录。 - 意向写入:各参与分片写入带事务 ID 的临时记录(
Provisional Records),不直接覆盖旧值。 - 提交裁决:全部参与分片确认后,状态分片将事务标记为
Committed,并分配最终HLC时间戳。 - 异步清理:后台将临时记录转正为带最终时间戳的正式版本;若读请求遇到临时记录,可回查状态分片判定可见性。
该机制将事务关键状态托管在受 Raft 保护的状态分片中,避免传统 2PC 协调者故障导致的长期阻塞问题。
全局数据分发与工程质量保障
除核心事务与一致性机制外,YugabyteDB 也在跨集群数据分发和可靠性工程方面投入了大量实践。
xCluster 异步复制与 CDC
在数据主权约束或超远距离部署下,同步复制成本可能不可接受。YugabyteDB 通过 xCluster 提供跨地域异步复制能力。
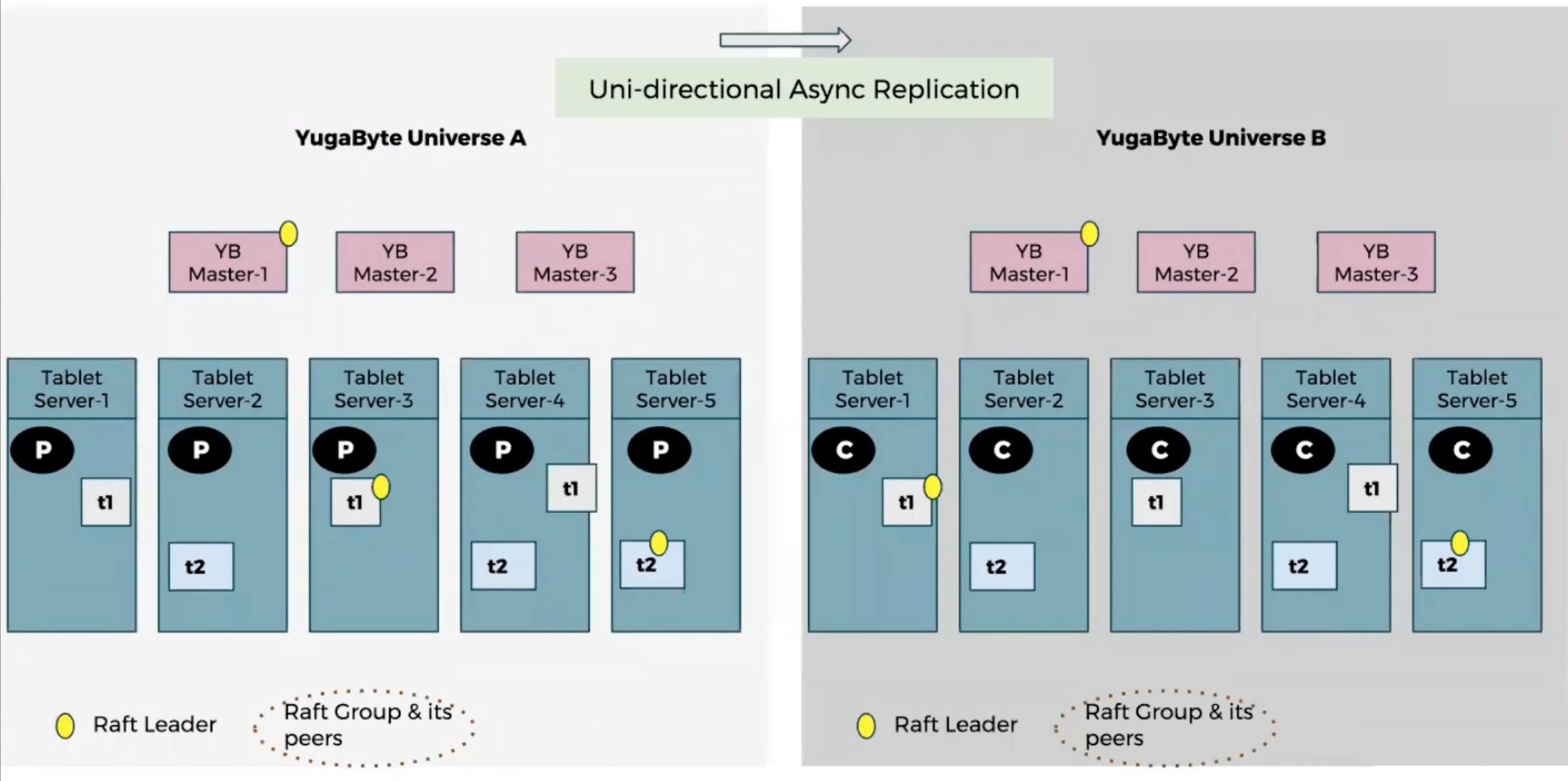
其底层依赖变更数据捕获(CDC, Change Data Capture):从 DocDB / Raft 变更日志提取数据变化,并通过 RPC 或 gRPC 推送到目标集群。该模式支持异地灾备、跨区域只读库等场景,实现跨集群存储与计算的进一步解耦。
CI/CD、混沌测试与一致性验证
分布式数据库对工程质量要求极高。YugabyteDB 在常规单元测试、压力测试之外,还结合内存与并发问题检查工具(如 Sanitizers)强化底层 C++ 质量控制。
更关键的是持续集成 Jepsen 混沌测试:模拟网络分区、时钟漂移、节点故障等极端场景,并在高并发事务压力下验证一致性语义(如避免脏读、丢失更新等)。只有通过这些校验的变更,才可进入发布链路。
同时,由于上层查询能力直接复用 PostgreSQL,系统在官方回归测试集上的表现也成为其兼容性与执行引擎成熟度的重要佐证。
结语
从内核实现与架构设计看,YugabyteDB 的价值在于将关系模型与云原生分布式能力进行工程化融合。它针对 Aurora 的单主写瓶颈与 Spanner 的硬件依赖分别给出可落地替代方案:上层复用 PostgreSQL,下层以 DocDB、增强 Raft、HLC 与事务状态分片协同实现强一致事务与弹性扩展。
这种“兼容成熟生态 + 重构分布式内核”的路线,标志着分布式关系型数据库在通用硬件与开源技术栈上的工程实现已进入成熟阶段。
欢迎关注
欢迎关注「端小强的博客」微信公众号,会不定期分享日常学习和工作经验,欢迎大家关注交流。
