
Calcite 扩展了 SQL 和关系代数以支持流式查询。
介绍
流是持续、永久流动的记录集合。与表不同,它们通常不存储在磁盘上,而是通过网络流动并在内存中短暂保存。
流是对表的补充,因为它们代表企业现在和未来正在发生的事情,而表则代表过去。将流归档到表中是很常见的操作。
与表一样,你通常希望使用基于关系代数的高级语言来查询流,根据模式进行验证,并进行优化以利用可用的资源和算法。
Calcite 的 SQL 是标准 SQL 的扩展,而不是另一种类 SQL 语言。这种区别很重要,原因如下:
- 对于任何了解常规 SQL 的人来说,流式 SQL 都很容易学习;
- 语义很清晰,因为我们的目标是在流上产生相同的结果,就像表中存在相同的数据一样;
- 你可以编写组合流和表(或流的历史记录,基本上是内存中的表)的查询;
- 许多现有工具可以生成标准 SQL。
如果不使用 STREAM 关键字,则会返回常规标准 SQL。
示例模式
我们的流式 SQL 示例使用以下模式:
Orders (rowtime, productId, orderId, units)——一个流和一张表;Products (rowtime, productId, name)——一张表;Shipments (rowtime, orderId)——一个流。
一个简单的查询
让我们从最简单的流式查询开始:
1 | SELECT STREAM * |
此查询从 Orders 流中读取所有列和行。与任何流式查询一样,它永远不会终止。每当记录到达 Orders 时,它就会输出一条记录。
输入 Control-C 终止查询。
STREAM 关键字是流式 SQL 中的主要扩展。它告诉系统你对新输入的订单感兴趣,而不是现有订单。如下查询:
1 | SELECT * |
也有效,但会打印出所有现有订单,然后终止。我们将其称为关系查询,而不是流式查询。它具有传统的 SQL 语义。
Orders 很特殊,因为它既有流又有表。如果您尝试在表上运行流式查询,或在流上运行关系查询,Calcite 会给出错误:
1 | SELECT * FROM Shipments; |
过滤行
就像在常规 SQL 中一样,您使用 WHERE 子句来过滤行:
1 | SELECT STREAM * |
投影表达式
在 SELECT 语句中使用表达式来选择要返回的列或计算表达式:
1 | SELECT STREAM rowtime, |
我们建议您始终在 SELECT 子句中包含 rowtime 列。在每个流和流查询中拥有排序的时间戳使得稍后可以进行高级计算,例如 GROUP BY 和 JOIN 。
滚动窗口(Tumbling windows)
有多种方法可以计算流上的聚合函数。它们的差异是:
- 每行输入多少行?
- 每个传入值是否出现在一个或多个总计中?
- 什么定义了
窗口,即构成给定输出行的行集? - 结果是流还是关系?
Calcite 有多种窗口类型:
- 滚动窗口
tumbling windows(GROUP BY); - 跳跃窗口
hopping window(多 GROUP BY); - 滑动窗口
sliding window(window 函数); - 级联窗口
cascading window(window 函数)。
下图显示了使用它们的查询类型:
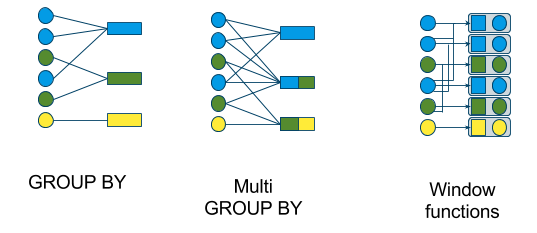
首先,我们来看一个滚动窗口,它由流式的 GROUP BY 定义。如下是示例 SQL:
1 | SELECT STREAM CEIL(rowtime TO HOUR) AS rowtime, |
结果是一个流。在 11 点钟,Calcite 会为自 10 点钟以来有订单的每个 productId 分组计数,时间戳为 11 点钟。 12点,它会统计11:00到12:00之间发生的订单。每个输入行仅被包含在一个输出的分组中。
Calcite 如何知道 10:00:00 的统计已在 11:00:00 完成,以便可以输出它们?因为 Calcite 知道 rowtime 正在增加,并且也知道 CEIL(rowtime TO HOUR) 在增加。因此,一旦它在 11:00:00 或之后看到了一行,它就永远不会看到对 10:00:00 统计有影响的数据行。
递增或递减的列或表达式被称为单调的。
如果列或表达式的值稍微乱序,并且流具有声明特定值将永远不会再次出现的机制(例如标点符号或水印),则该列或表达式被称为准单调。
如果 GROUP BY 子句中没有单调或准单调表达式,Calcite 就无法取得进展,并且不允许查询:
1 | SELECT STREAM productId, |
单调和准单调列需要在模式中声明。当记录进入流时,单调性被强制执行,并且从该流读取的查询假定了数据具有单调性。我们建议你为每个流提供一个名为 rowtime 的时间戳列,但你也可以将其他列声明为单调的,例如 orderId 。
我们在下面讨论标点符号、水印和其他取得进展的方法。
改进的滚动窗口
前面的滚动窗口示例很容易编写,因为窗口为一小时。对于不是整个时间单位的间隔,例如 2 小时或 2 小时 17 分钟,你不能使用 CEIL ,并且表达式会变得更加复杂。
Calcite 支持滚动窗口的替代语法:
1 | SELECT STREAM TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS rowtime, |
如你所见,它返回与上一个查询相同的结果。 TUMBLE 函数会返回一个分组键,该键在最终输出的统计结果中会保持相同; TUMBLE_END 函数采用相同的参数并返回该窗口结束的时间;此外还有一个 TUMBLE_START 函数。
TUMBLE 有一个可选参数来对齐窗口。在以下示例中,我们使用 30 分钟间隔和 0:12 作为对齐时间,因此查询会在每小时过去 12 和 42 分钟输出结果:
1 | SELECT STREAM |
跳跃窗口(Hopping windows)
跳跃窗口是滚动窗口的泛化,它允许数据在窗口中保留的时间长于输出间隔。
例如,以下查询输出时间戳为 11:00 的行,其中包含从 08:00 到 11:00 的数据(如果我们比较迂腐的话,则为 10:59.9),而时间戳为 12:00 的行包含从 09:00 到 12:00 的数据。
1 | SELECT STREAM |
在此查询中,由于保留期是输出期的 3 倍,因此每个输入行正好贡献 3 个输出行。想象一下 HOP 函数为输入行生成一组分组键的集合,并将其值放入每个分组键的累加器中。例如, HOP(10:18:00, INTERVAL '1' HOUR, INTERVAL '3') 生成 3 个时间段。
1 | [08:00, 09:00) [09:00, 10:00) [10:00, 11:00) |
这为那些对内置函数 HOP 和 TUMBLE 不满意的用户提供了允许用户定义分区函数的可能性。
我们可以构建复杂的复杂表达式,例如指数衰减的移动平均线:
1 | SELECT STREAM HOP_END(rowtime), |
它会输出:
11:00:00处的一行包含[10:00:00, 11:00:00)中的行;11:00:01处的行包含[10:00:01, 11:00:01)中的行。
该表达式对最近订单的权重比对旧订单的权重更大。将窗口从 1 小时延长到 2 小时或 1 年实际上对结果的准确性没有影响(但会使用更多的内存和计算)。
请注意,我们在聚合函数 ( SUM ) 中使用 HOP_START ,因为它是一个对于统计中所有行而言都是恒定的值。对于典型的聚合函数( SUM 、 COUNT 等),这是不允许的。
如果您熟悉 GROUPING SETS ,您可能会注意到分区函数可以被视为 GROUPING SETS 的泛化,因为它们允许输入行参与多个统计。 GROUPING SETS 的辅助函数,例如 GROUPING() 和 GROUP_ID ,可以在聚合函数内部使用,因此 HOP_START 并不奇怪和 HOP_END 可以以相同的方式使用。
分组集
GROUPING SETS 对于流式查询有效,前提是每个分组集都包含单调或准单调表达式。
CUBE 和 ROLLUP 对于流式查询无效,因为它们将生成至少一个聚合所有内容的分组集(如 GROUP BY () )。
聚合后过滤
与标准 SQL 中一样,你可以应用 HAVING 子句来过滤流 GROUP BY 输出的行:
1 | SELECT STREAM TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS rowtime, |
子查询、视图和 SQL 的闭包属性
前面的 HAVING 查询可以使用子查询上的 WHERE 子句来表示:
1 | SELECT STREAM rowtime, productId |
HAVING 是在 SQL 早期引入的,当时需要一种方法来在聚合后执行过滤器。 (回想一下, WHERE 在行进入 GROUP BY 子句之前过滤行。)
从那时起,SQL 就成为一种数学封闭语言,这意味着您可以对表执行的任何操作也可以对查询执行。
SQL的闭包特性非常强大。它不仅使 HAVING 过时(或者至少将其简化为语法糖),而且使视图成为可能:
1 | CREATE VIEW HourlyOrderTotals (rowtime, productId, c, su) AS |
FROM 子句中的子查询有时称为内联视图,但实际上,它们比视图更基本。视图只是一种方便的方法,通过给片段命名并将它们存储在元数据存储库中,将 SQL 分割成可管理的块。
许多人发现嵌套查询和视图在流上比在关系上更有用。流式查询是所有连续运行的运算符管道,并且这些管道通常会变得很长。嵌套查询和视图有助于表达和管理这些管道。
顺便说一句, WITH 子句可以完成与子查询或视图相同的功能:
1 | WITH HourlyOrderTotals (rowtime, productId, c, su) AS ( |
流和关系之间的转换
回顾一下 HourlyOrderTotals 视图的定义。视图是流还是关系?
它不包含 STREAM 关键字,因此它是一个关系。然而,它是一种可以转换为流的关系。
您可以在关系查询和流查询中使用它:
1 | # A relation; will query the historic Orders table. |
这种方法不限于视图和子查询。按照 CQL[1] 中规定的方法,流式 SQL 中的每个查询都被定义为关系查询,并使用最顶层 SELECT 中的 STREAM 关键字转换为流。
如果 STREAM 关键字出现在子查询或视图定义中,则它不起作用。
在查询准备时,Calcite 会确定查询中引用的关系是否可以转换为流或历史关系。
有时,流会提供其部分历史记录(例如 Apache Kafka[2] 主题中最近 24 小时的数据),但不是全部。在运行时,Calcite 会确定是否有足够的历史记录来运行查询,如果没有,则给出错误。
饼图问题:流上的关系查询
需要将流转换为关系的一种特殊情况发生在我所说的饼图问题中。想象一下,您需要编写一个带有图表的网页,如下所示,该图表总结了过去一小时内每种产品的订单数量。
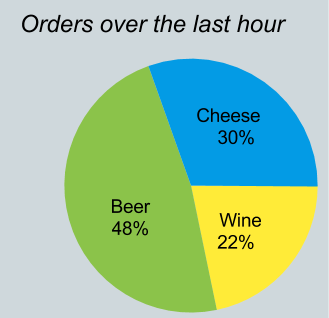
但是 Orders 流只包含一些记录,而不是一个小时的统计。我们需要对流的历史记录运行关系查询:
1 | SELECT productId, count(*) |
如果 Orders 流的历史记录被写入到 Orders 表,我们就可以返回查询,尽管这样成本很高。如果我们能够告诉系统将一小时的统计具体化到一个表中,随着流的流动不断维护它,并自动重写查询以使用该表,那就更好了。
排序
ORDER BY 的故事与 GROUP BY 类似。语法看起来与常规 SQL 类似,但 Calcite 必须确保它能够及时提供结果。因此,它需要在 ORDER BY 键的前面有一个单调的表达式。
1 | SELECT STREAM CEIL(rowtime TO hour) AS rowtime, productId, orderId, units |
大多数查询将按照插入的顺序返回结果,因为引擎使用流算法,但您不应该依赖它。例如,考虑一下:
1 | SELECT STREAM * |
productId = 30 的行显然是无序的,可能是因为 Orders 流在 productId 上分区,并且分区流在不同时间发送数据。
如果您需要特定的顺序,请添加明确的 ORDER BY :
1 | SELECT STREAM * |
Calcite 可能会通过使用 rowtime 合并来实现 UNION ALL ,这只是效率稍低一些。
您只需要在最外面的查询中添加 ORDER BY 即可。例如,如果您需要在 UNION ALL 之后执行 GROUP BY ,Calcite 将隐式添加 ORDER BY ,以使 GROUP BY 算法成为可能。
表构造函数
VALUES 子句创建一个包含给定行集的内联表。
VALUES 子句不允许流式传输。行集永远不会改变,因此流永远不会返回任何行。
1 | > SELECT STREAM * FROM (VALUES (1, 'abc')); |
滑动窗口(Sliding windows)
标准 SQL 具有所谓的分析函数,可以在 SELECT 子句中使用。与 GROUP BY 不同,它们不会折叠记录。每输入一条记录,就会输出一条记录。但聚合函数是基于多行的窗口。
让我们看一个例子。
1 | SELECT STREAM rowtime, |
该功能毫不费力即可提供强大的功能。根据多窗口使用规范,您可以在 SELECT 子句中使用多个函数。
以下示例返回过去 10 分钟平均订单大小大于上周平均订单大小的订单。
1 | SELECT STREAM * |
为了简洁起见,这里我们使用这样的语法:使用 WINDOW 子句部分定义窗口,然后在每个 OVER 子句中细化窗口。如果你愿意,你还可以在 WINDOW 子句中定义所有窗口,或内联所有窗口。
但真正的力量超越了语法。在幕后,该查询维护两个表,并使用 FIFO 队列在小计中添加和删除值。但是您可以访问这些表,而无需在查询中引入联接。
窗口聚合语法的一些其他功能:
- 你可以根据行数定义窗口;
- 该窗口可以引用尚未到达的行(流将等待,直到他们到达);
- 你可以计算与顺序相关的函数,例如
RANK和中位数。
级联窗口(Cascading windows)
如果我们想要一个为每条记录返回结果的查询(如滑动窗口),但在固定时间段重置总计(如滚动窗口),该怎么办?这种模式称为级联窗口。这是一个例子:
1 | SELECT STREAM rowtime, |
它看起来类似于滑动窗口查询,但单调表达式出现在窗口的 PARTITION BY 子句中。随着行时间从 10:59:59 移动到 11:00:00, FLOOR(rowtime TO HOUR) 从 10:00:00 更改为 11:00:00,会开始一个新分区。在新的小时到达的第一行将开始新的总计;第二行的总计由两行组成,依此类推。
Calcite 知道旧分区将永远不会再次使用,因此会从其内部存储中删除该分区的所有统计。
使用级联和滑动窗口的分析函数可以组合在同一个查询中。
流和表关联
涉及流的关联有两种:流到表关联和流到流关联。
如果表的内容没有改变,那么流到表的关联就很简单。此查询通过每种产品的标价丰富了订单流:
1 | SELECT STREAM o.rowtime, o.productId, o.orderId, o.units, |
如果表发生变化会发生什么?例如,假设产品 10 的单价在 11:00 增加到 0.35。 11:00之前下的订单应采用旧价格,11:00之后下的订单应采用新价格。
实现此目的的一种方法是使用一个表来保存每个版本的开始和结束有效日期,在以下示例中为 ProductVersions :
1 | SELECT STREAM * |
实现此目的的另一种方法是使用具有时间支持的数据库(能够查找过去任何时刻的数据库内容),并且系统需要知道 rowtime Orders 流的列对应于 Products 表的事务时间戳。
对于许多应用程序来说,不值得花费时间支持或版本化表的成本和精力。应用程序可以接受查询在重播时给出不同的结果:在此示例中,在重播时,产品 10 的所有订单都被分配了较晚的单价 0.35。
流和流关联
如果连接条件以某种方式使得两个流彼此保持有限距离,则关联两个流是有意义的。在以下查询中,发货日期在订单日期的一小时内:
1 | SELECT STREAM o.rowtime, o.productId, o.orderId, s.rowtime AS shipTime |
请注意,相当多的订单没有出现,因为它们在一小时内没有发货。当系统收到时间戳为 11:24:11 的订单 10 时,它已经从哈希表中删除了时间戳为 10:18:07 的订单 8(含)之前的订单。
正如您所看到的,将两个流的单调或准单调列关联在一起的锁定步骤对于系统取得进展是必要的。如果它不能推断出锁定步骤,它将拒绝执行查询。
数据管理语言(DML)
不仅查询语句能够支持流操作,而且 DML 语句(( INSERT 、 UPDATE 、 DELETE 以及它们衍生的 UPSERT 和 REPLACE)也支持流操作。
DML 很有用,因为它允许你具体化流或基于流的表,因此在经常使用值时可以节省精力。
考虑流应用程序通常由查询管道组成,每个查询将输入流转换为输出流。管道的组件可以是视图:
1 | CREATE VIEW LargeOrders AS |
或标准的 INSERT 声明:
1 | INSERT INTO LargeOrders |
它们看起来很相似,并且在这两种情况下,管道中的下一步都可以从 LargeOrders 读取,而不必担心它是如何填充的。效率上有区别:无论有多少个消费者, INSERT 语句都做同样的工作。而视图的工作与消费者的数量成正比,特别是如果没有消费者,则该视图不起作用。
其他形式的 DML 对流也有意义。例如,以下标准的 UPSERT 语句维护一个表,该表具体化了最后一小时订单的统计:
1 | UPSERT INTO OrdersSummary |
标点符号(Punctuation)
即使单调键中没有足够的值来推出结果,标点符号[3]也允许流查询取得进展(我更喜欢术语是行时间边界,水印[4]是一个相关概念,但出于这些目的,标点符号就足够了)。
如果流启用了标点符号,则它可能无法排序,但仍然可以排序。因此,出于语义目的,按照排序流进行工作就足够了。
顺便说一句,如果无序流是 t 排序的(即每条记录保证在其时间戳的 t 秒内到达)或 k 排序的(即每条记录保证不超过k 个位置乱序)。因此,对这些流的查询可以与对带有标点符号的流的查询类似地进行规划。
而且,我们经常希望聚合不基于时间但仍然单调的属性。 一支球队在获胜状态和失败状态之间转换的次数就是这样一个单调属性。系统需要自己弄清楚聚合这样的属性是安全的;标点符号不添加任何额外信息。
我想到了优化器的一些元数据(成本指标):
- 该流是否根据给定的属性(或多个属性)排序?
- 是否可以根据给定属性对流进行排序? (对于有限关系,答案始终是
是;对于流,它取决于标点符号的存在或属性和排序键之间的链接); - 为了执行这种排序,我们需要引入什么延迟?
- 执行该排序的成本是多少(CPU、内存等)?
我们在 BuiltInMetadata.Collation 中已经有了(1)。对于 (2),对于有限关系,答案始终为真。但我们需要为流实现 (2)、(3) 和 (4)。
流的状态
并非本文中的所有概念都已在 Calcite 中实现。其他的可能在 Calcite 中实现,但不能在 SamzaSQL [5] [6] 等特定适配器中实现。
已实现
- 流式的
SELECT、WHERE、GROUP BY、HAVING、UNION ALL、ORDER BY; FLOOR和CEIL函数;- 单调性;
- 不允许流式的
VALUES。
未实现
本文档中提供了以下功能,就好像方解石支持它们一样,但实际上它(尚未)不支持。完全支持意味着参考实现支持该功能(包括负面情况)并且 TCK 对其进行了测试。
- 流到流
JOIN; - 流到表
JOIN; - 流式视图;
- 带有
ORDER BY的流式UNION ALL(需要合并); - 流式关系查询;
- 流式窗口聚合(滑动和级联窗口);
- 检查子查询和视图中的
STREAM是否被忽略; - 检查流式
ORDER BY不能有OFFSET或LIMIT; - 有限的历史——在运行时,检查是否有足够的历史记录来运行查询;
- 准单调性;
HOP和TUMBLE(以及辅助HOP_START、HOP_END、TUMBLE_START、TUMBLE_END)功能。
文档中待办事项
- 重新访问是否可以流式执行
VALUES; OVER子句定义流上的窗口;- 考虑是否在流式查询中允许
CUBE和ROLLUP,并了解某些级别的聚合永远不会完成(因为它们没有单调表达式),因此永远不会被输出; - 修复
UPSERT示例以删除过去一小时内未出现的产品记录; - 输出到多个流的DML;也许是标准
REPLACE语句的扩展。
功能
以下函数不存在于标准 SQL 中,但在流 SQL 中定义。
标量函数:
FLOOR(dateTime TO intervalType)将日期、时间或时间戳值向下舍入为给定的间隔类型;CEIL(dateTime TO intervalType)将日期、时间或时间戳值四舍五入到给定的间隔类型。
分区函数:
HOP(t, emit, retain)返回作为跳跃窗口一部分的行的组键集合;HOP(t, emit, retain, align)返回作为具有给定对齐方式的跳跃窗口一部分的行的组键的集合;TUMBLE(t, emit)返回作为滚动窗口一部分的行的组键;TUMBLE(t, emit, align)返回作为具有给定对齐方式的翻滚窗口一部分的行的组键。
TUMBLE(t, e) 相当于 TUMBLE(t, e, TIME '00:00:00') 。
TUMBLE(t, e, a) 相当于 HOP(t, e, e, a) 。
HOP(t, e, r) 相当于 HOP(t, e, r, TIME '00:00:00') 。
写在最后
笔者因为工作原因接触到 Calcite,前期学习过程中,深感 Calcite 学习资料之匮乏,因此创建了 Calcite 从入门到精通知识星球,希望能够将学习过程中的资料和经验沉淀下来,为更多想要学习 Calcite 的朋友提供一些帮助。

参考文档
Arvind Arasu, Shivnath Babu, and Jennifer Widom (2003) The CQL Continuous Query Language: Semantic Foundations and Query Execution. ↩︎
Peter A. Tucker, David Maier, Tim Sheard, and Leonidas Fegaras (2003) Exploiting Punctuation Semantics in Continuous Data Streams. ↩︎
Tyler Akidau, Alex Balikov, Kaya Bekiroglu, Slava Chernyak, Josh Haberman, Reuven Lax, Sam McVeety, Daniel Mills, Paul Nordstrom, and Sam Whittle (2013) MillWheel: Fault-Tolerant Stream Processing at Internet Scale. ↩︎