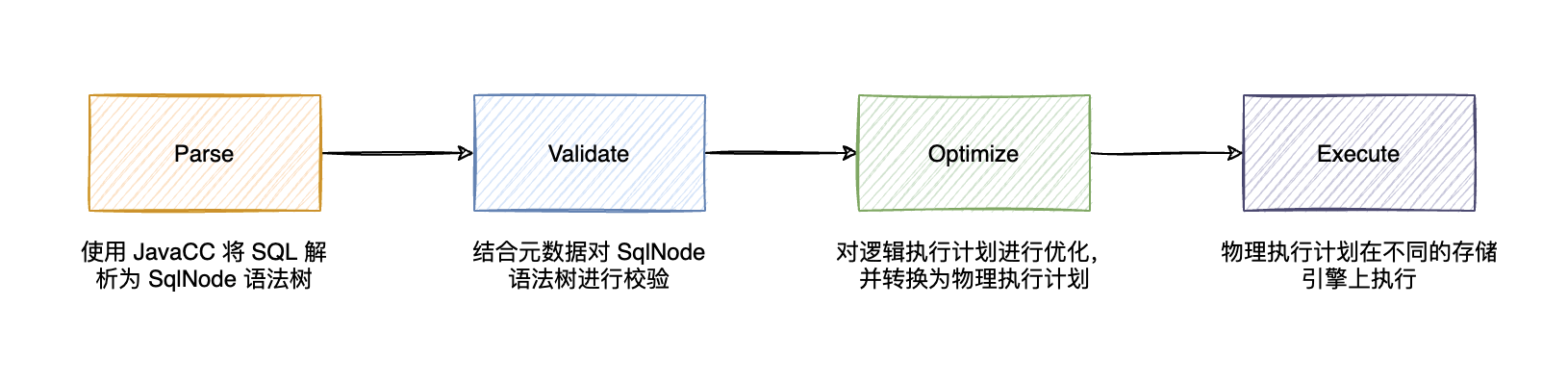
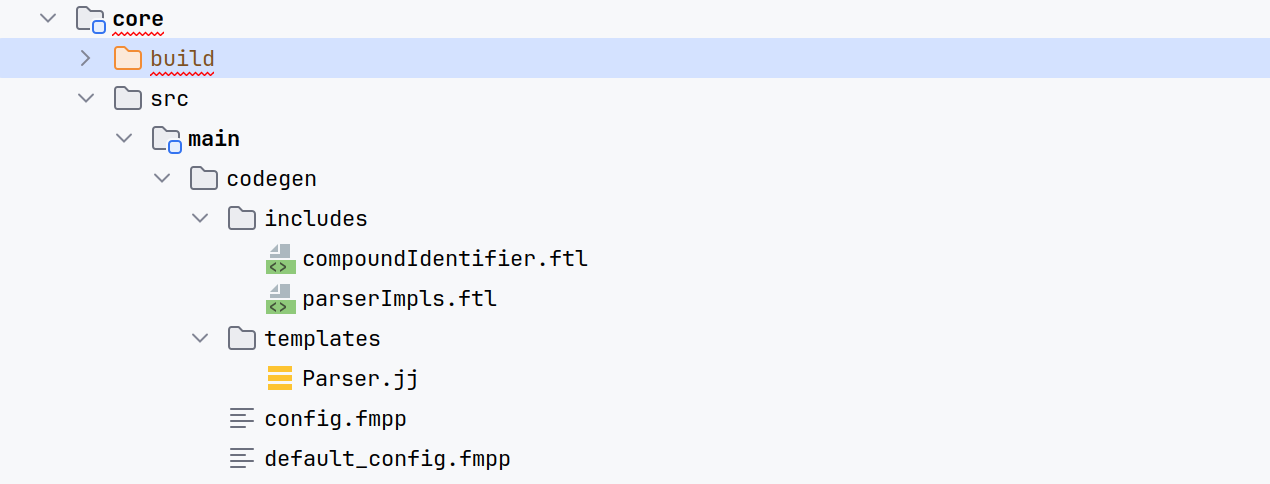
Java Compiler Compiler (JavaCC) is the most popular parser generator for use with Java applications. A parser generator is a tool that reads a grammar specification and converts it to a Java program that can recognize matches to the grammar. In addition to the parser generator itself, JavaCC provides other standard capabilities related to parser generation such as tree building (via a tool called JJTree included with JavaCC), actions and debugging.
/* Lexical states: DEFAULT: Identifiers are quoted in brackets, e.g. [My Identifier] DQID: Identifiers are double-quoted, e.g. "My Identifier" BTID: Identifiers are enclosed in back-ticks, escaped using back-ticks, e.g. `My ``Quoted`` Identifier` BQID: Identifiers are enclosed in back-ticks, escaped using backslash, e.g. `My \`Quoted\` Identifier`, and with the potential to shift into BQHID in contexts where table names are expected, and thus allow hyphen-separated identifiers as part of table names BQHID: Identifiers are enclosed in back-ticks, escaped using backslash, e.g. `My \`Quoted\` Identifier` and unquoted identifiers may contain hyphens, e.g. foo-bar IN_SINGLE_LINE_COMMENT: IN_FORMAL_COMMENT: IN_MULTI_LINE_COMMENT: DEFAULT, DQID, BTID, BQID are the 4 'normal states'. Behavior is identical except for how quoted identifiers are recognized. The BQHID state exists only at the start of a table name (e.g. immediately after FROM or INSERT INTO). As soon as an identifier is seen, the state shifts back to BTID. After a comment has completed, the lexer returns to the previous state, one of the 'normal states'. */
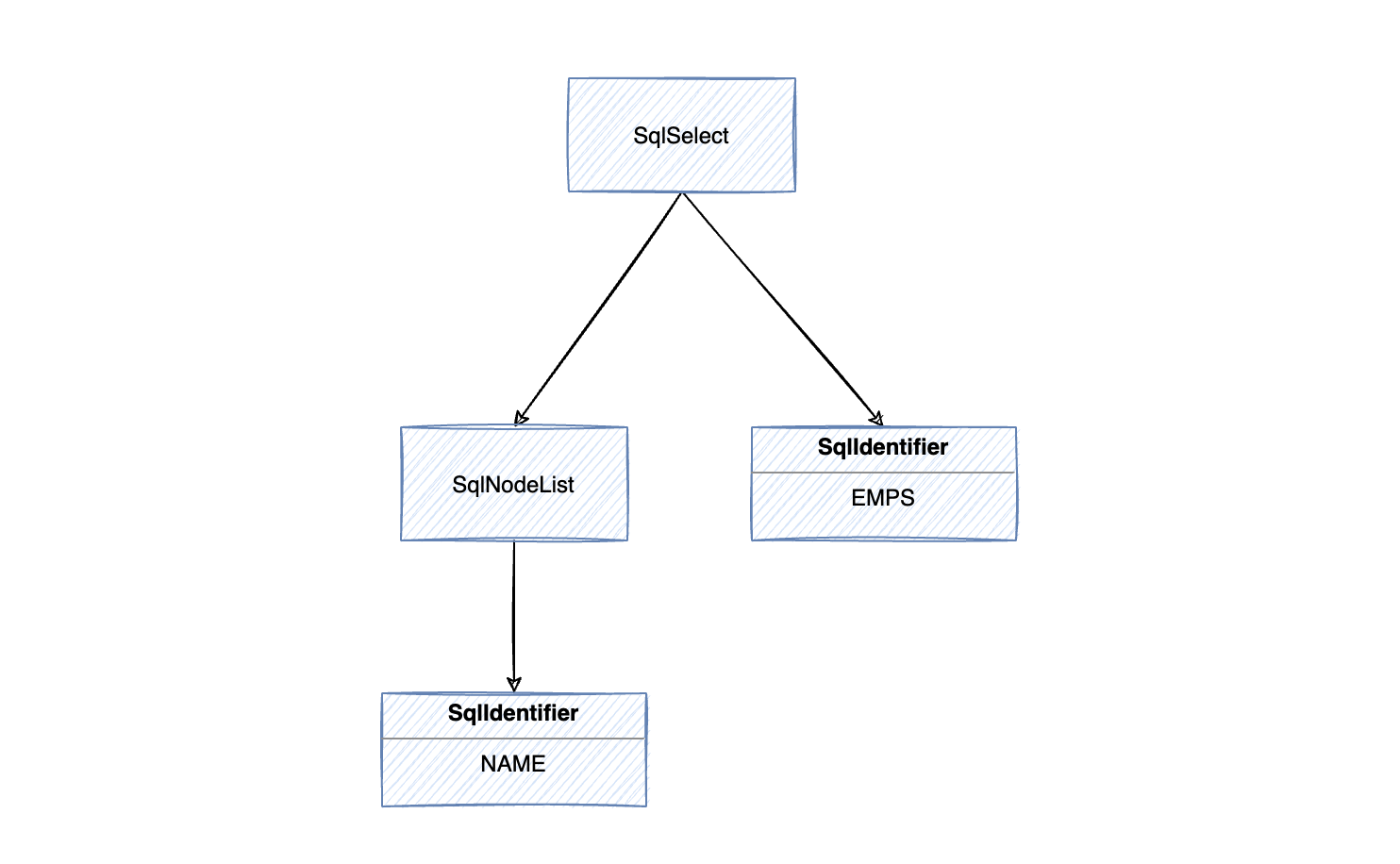
Stringsql="select name from EMPS"; SqlParsersqlParser= SqlParser.create(sql, Config.DEFAULT); SqlNodesqlNode= sqlParser.parseQuery(); System.out.println(sqlNode.toSqlString(MysqlSqlDialect.DEFAULT));
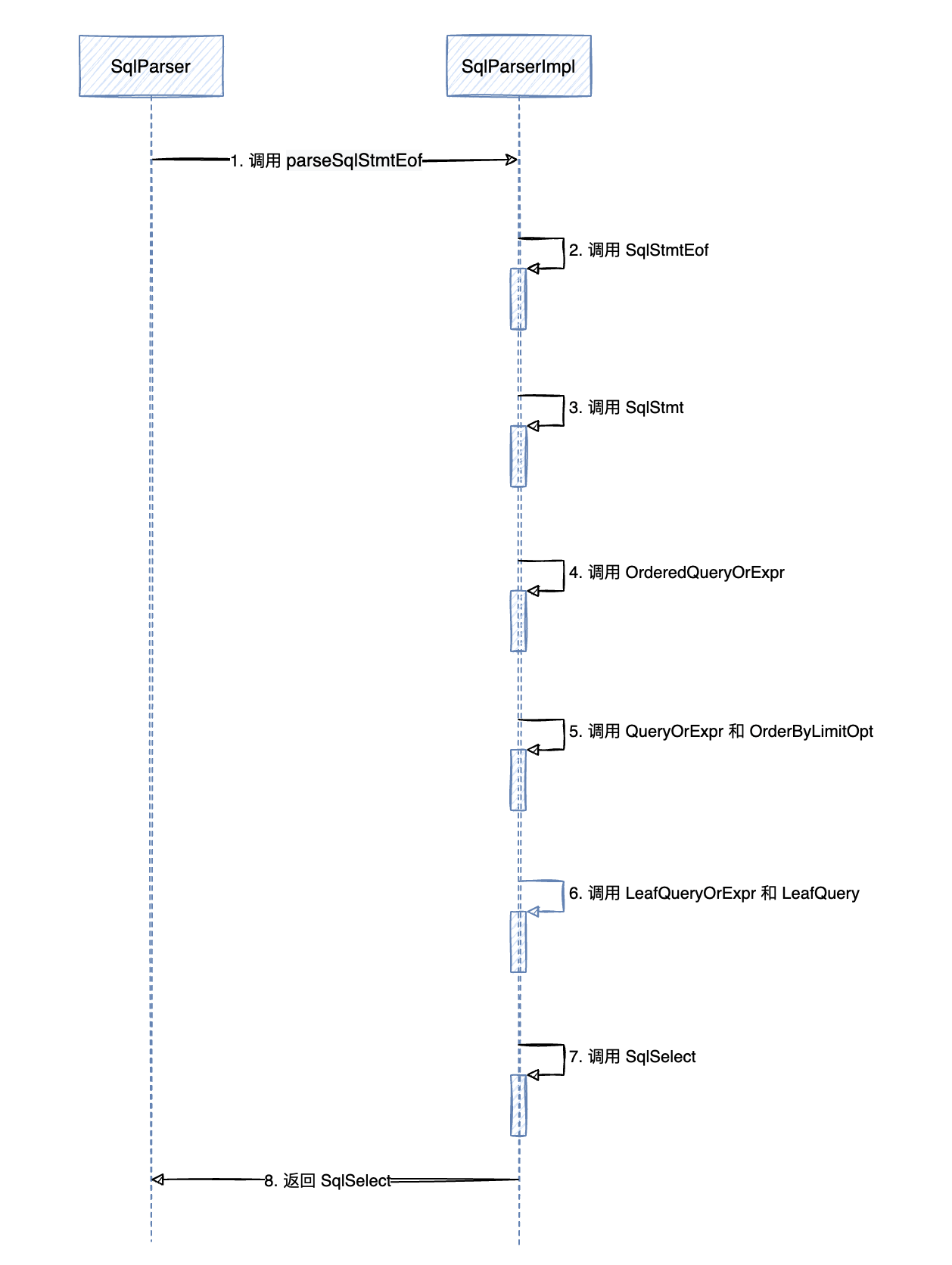
/** * Parses a <code>SELECT</code> statement. * * @return A {@link org.apache.calcite.sql.SqlSelect} for a regular <code> * SELECT</code> statement; a {@link org.apache.calcite.sql.SqlBinaryOperator} * for a <code>UNION</code>, <code>INTERSECT</code>, or <code>EXCEPT</code>. * @throws SqlParseException if there is a parse error */ public SqlNode parseQuery()throws SqlParseException { try { return parser.parseSqlStmtEof(); } catch (Throwable ex) { throw handleException(ex); } }
val fmppMain by tasks.registering(org.apache.calcite.buildtools.fmpp.FmppTask::class) { config.set(file("src/main/codegen/config.fmpp")) templates.set(file("src/main/codegen/templates")) }
val javaCCMain by tasks.registering(org.apache.calcite.buildtools.javacc.JavaCCTask::class) { dependsOn(fmppMain) val parserFile = fmppMain.map { it.output.asFileTree.matching { include("**/Parser.jj") } } inputFile.from(parserFile) packageName.set("org.apache.calcite.sql.parser.impl") }
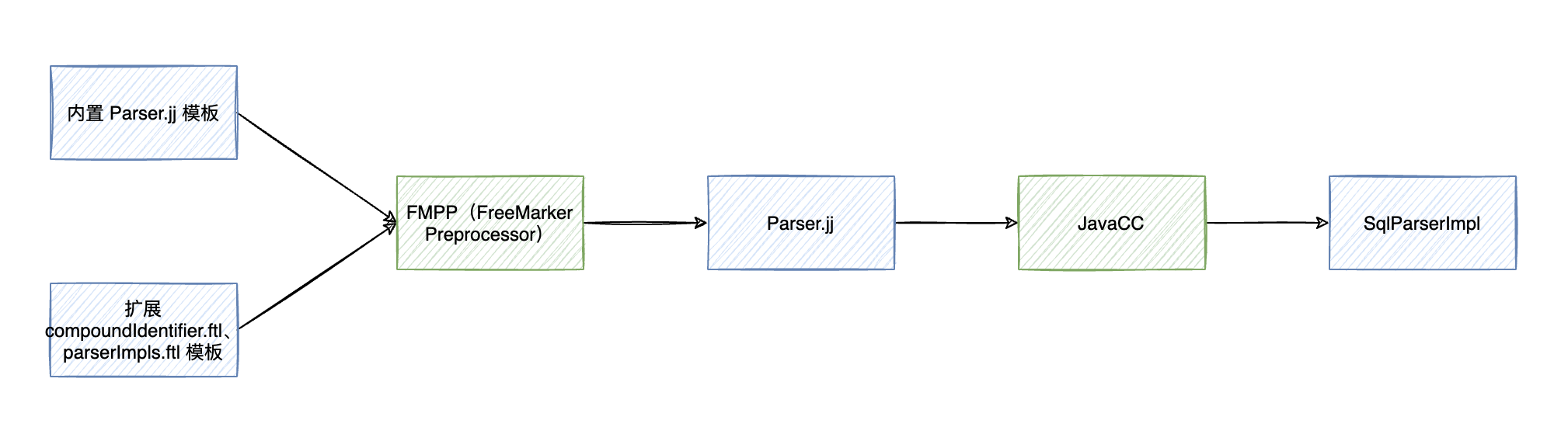
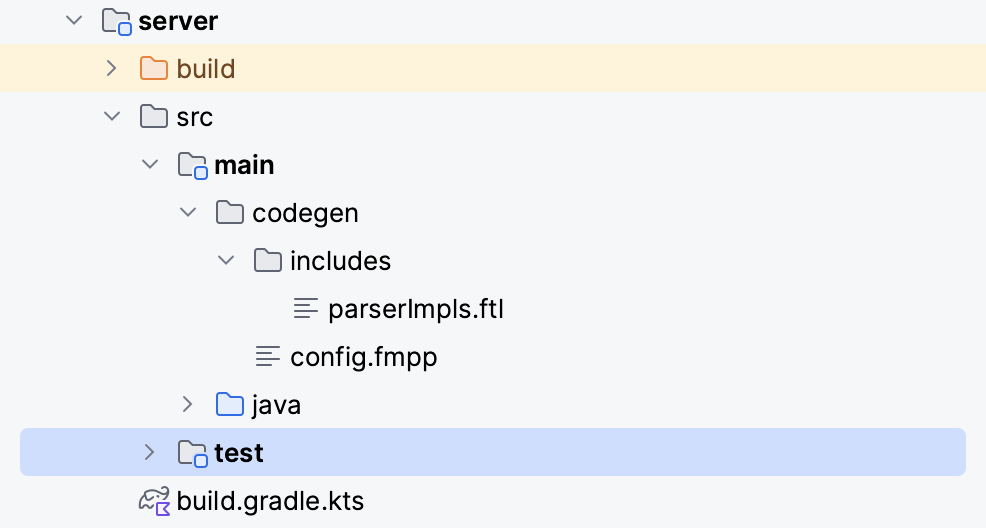
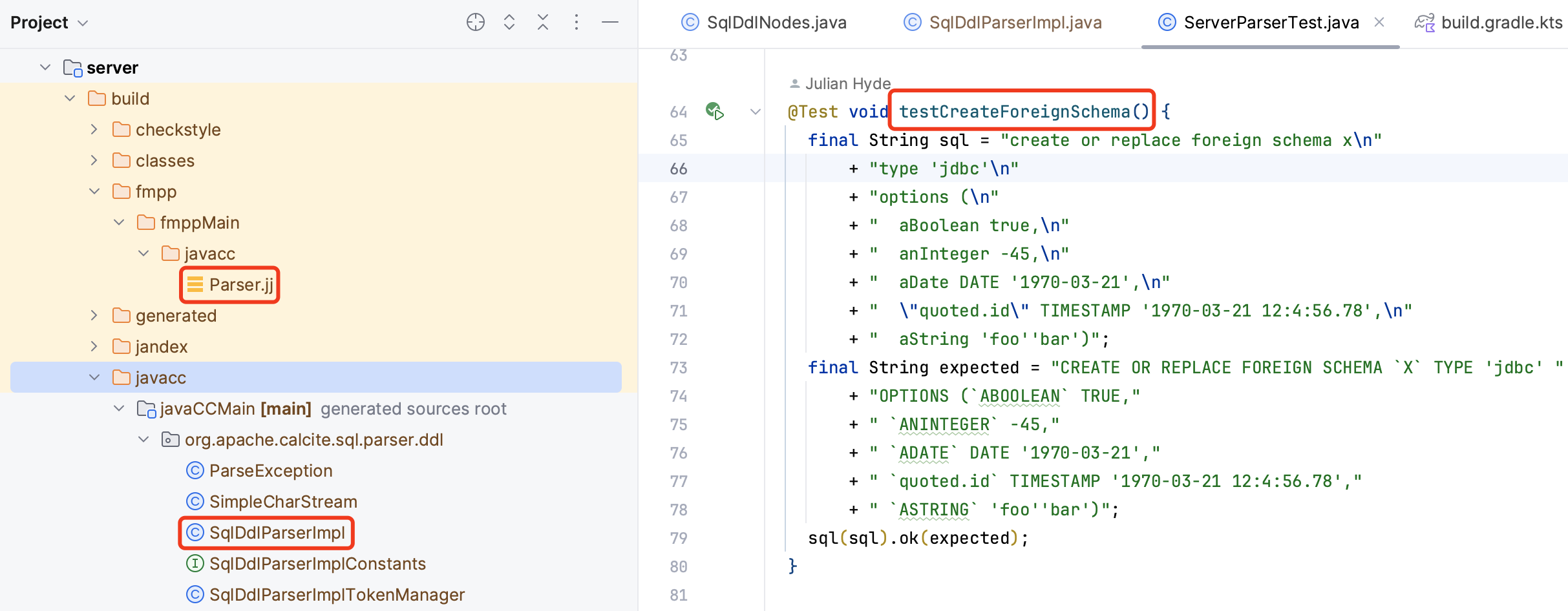
了解了 Calcite SQL Parser 语法扩展的流程后,我们再来看一个语法扩展的例子。在 server 模块,Calcite 使用相同的扩展方法,增加了对 DDL 语句的支持。下图展示了 server 模块语法扩展使用到的文件——config.fmpp 和 parserImpls.ftl。
data:{ # Data declarations for this parser. # # Default declarations are in default_config.fmpp; if you do not include a # declaration ('imports' or 'nonReservedKeywords', for example) in this file, # FMPP will use the declaration from default_config.fmpp. parser:{ # Generated parser implementation class package and name package:"org.apache.calcite.sql.parser.ddl", class:"SqlDdlParserImpl",
# List of import statements. imports:[ "org.apache.calcite.schema.ColumnStrategy" "org.apache.calcite.sql.SqlCreate" "org.apache.calcite.sql.SqlDrop" "org.apache.calcite.sql.SqlTruncate" "org.apache.calcite.sql.ddl.SqlDdlNodes" ]
# List of new keywords. Example:"DATABASES","TABLES". If the keyword is # not a reserved keyword, add it to the 'nonReservedKeywords' section. keywords:[ "IF" "MATERIALIZED" "STORED" "VIRTUAL" "JAR" "FILE" "ARCHIVE" ]
# List of non-reserved keywords to add; # items in this list become non-reserved nonReservedKeywordsToAdd:[ # not in core, added in server "IF" "MATERIALIZED" "STORED" "VIRTUAL" "JAR" "FILE" "ARCHIVE" ]
# List of methods for parsing extensions to "CREATE [OR REPLACE]" calls. # Each must accept arguments "(SqlParserPos pos, boolean replace)". # Example:"SqlCreateForeignSchema". createStatementParserMethods:[ "SqlCreateForeignSchema" "SqlCreateMaterializedView" "SqlCreateSchema" "SqlCreateTable" "SqlCreateType" "SqlCreateView" "SqlCreateFunction" ]
# List of methods for parsing extensions to "DROP" calls. # Each must accept arguments "(SqlParserPos pos)". # Example:"SqlDropSchema". dropStatementParserMethods:[ "SqlDropMaterializedView" "SqlDropSchema" "SqlDropTable" "SqlDropType" "SqlDropView" "SqlDropFunction" ]
# List of methods for parsing extensions to "TRUNCATE" calls. # Each must accept arguments "(SqlParserPos pos)". # Example:"SqlTruncateTable". truncateStatementParserMethods:[ "SqlTruncateTable" ]
# List of files in @includes directory that have parser method # implementations for parsing custom SQL statements, literals or types # given as part of "statementParserMethods","literalParserMethods" or # "dataTypeParserMethods". # Example:"parserImpls.ftl". implementationFiles:[ "parserImpls.ftl" ] } }
val fmppMain by tasks.registering(org.apache.calcite.buildtools.fmpp.FmppTask::class) { inputs.dir("src/main/codegen").withPathSensitivity(PathSensitivity.RELATIVE) config.set(file("src/main/codegen/config.fmpp")) templates.set(file("$rootDir/core/src/main/codegen/templates")) }
val javaCCMain by tasks.registering(org.apache.calcite.buildtools.javacc.JavaCCTask::class) { dependsOn(fmppMain) val parserFile = fmppMain.map { it.output.asFileTree.matching { include("**/Parser.jj") } } inputFile.from(parserFile) packageName.set("org.apache.calcite.sql.parser.ddl") }
/** * A <code>SqlSelect</code> is a node of a parse tree which represents a select * statement. It warrants its own node type just because we have a lot of * methods to put somewhere. */ publicclassSqlSelectextendsSqlCall { //~ Static fields/initializers ---------------------------------------------
// Override SqlCall, to introduce a sub-query frame. @Override publicvoidunparse(SqlWriter writer, int leftPrec, int rightPrec) { if (!writer.inQuery() || getFetch() != null && (leftPrec > SqlInternalOperators.FETCH.getLeftPrec() || rightPrec > SqlInternalOperators.FETCH.getLeftPrec()) || getOffset() != null && (leftPrec > SqlInternalOperators.OFFSET.getLeftPrec() || rightPrec > SqlInternalOperators.OFFSET.getLeftPrec()) || getOrderList() != null && (leftPrec > SqlOrderBy.OPERATOR.getLeftPrec() || rightPrec > SqlOrderBy.OPERATOR.getRightPrec())) { // If this SELECT is the topmost item in a sub-query, introduce a new // frame. (The topmost item in the sub-query might be a UNION or // ORDER. In this case, we don't need a wrapper frame.) final SqlWriter.Frameframe= writer.startList(SqlWriter.FrameTypeEnum.SUB_QUERY, "(", ")"); writer.getDialect().unparseCall(writer, this, 0, 0); writer.endList(frame); } else { writer.getDialect().unparseCall(writer, this, leftPrec, rightPrec); } }
由于我们示例中生成的是 MySQL 的方言,因此调用的是 MysqlSqlDialect#unparseCall 方法,具体实现逻辑如下。前文我们介绍了 SqlCall 的用于,它代表了对 SqlOperator 的调用,此处为 SqlSelectOperator,它对应的 SqlKind 为 SELECT,因此会先调用 super.unparseCall 方法。可以看到,除了 default 分支外,其他分支在处理不同方言的差异,例如:将 POSITION 操作转换成 MySQL 中的 INSTR,将 LISTAGG 转换为 MySQL 中的 GROUP_CONCAT。
publicvoidunparseCall(SqlWriter writer, SqlCall call, int leftPrec, int rightPrec) { SqlOperatoroperator= call.getOperator(); switch (call.getKind()) { case ROW: // Remove the ROW keyword if the dialect does not allow that. if (!getConformance().allowExplicitRowValueConstructor()) { if (writer.isAlwaysUseParentheses()) { // If writer always uses parentheses, it will have started parentheses // that we now regret. Use a special variant of the operator that does // not print parentheses, so that we can use the ones already started. operator = SqlInternalOperators.ANONYMOUS_ROW_NO_PARENTHESES; } else { // Use an operator that prints "(a, b, c)" rather than // "ROW (a, b, c)". operator = SqlInternalOperators.ANONYMOUS_ROW; } } // fall through default: operator.unparse(writer, call, leftPrec, rightPrec); } }